作为一名 SRE,网络是我们最常打交道但也最容易”背锅”的基础设施。当服务不可用时,”网络抖动”往往成为最万能的借口。但作为专业的可靠性工程师,我们需要深入理解网络协议的底层机制,才能在复杂的分布式系统中快速定位并解决问题。
本文将从 SRE 的视角出发,重新审视网络协议与通信的核心知识。
1. 情境 (Situation)
在微服务架构和云原生时代,网络通信不再是简单的客户端到服务器的连接。
- 服务网格 (Service Mesh):引入了 Sidecar 代理,增加了网络跳数。
- 容器网络 (CNI):Overlay 网络让数据包的封装解封装变得更加复杂。
- 全球负载均衡:DNS 解析和 Anycast 技术让流量调度变得不可见。
网络已经成为现代分布式系统的”循环系统”,其健康状况直接决定了业务的可用性。
2. 冲突 (Conflict)
然而,我们往往陷入了“网络是可靠的”这一误区(分布式计算的第一谬误)。 在实际生产环境中:
- TCP 连接不释放:导致文件句柄耗尽 (Too many open files)。
- DNS 解析延迟:导致服务间调用出现偶发性超时。
- 拥塞控制算法不匹配:导致高带宽环境下吞吐量上不去。
当这些问题发生时,如果我们只懂 ping 和 telnet,面对复杂的抓包数据和内核参数将束手无策。
3. 问题 (Question)
如何构建一套完整的网络知识体系,并掌握核心的排查工具,从而在遇到”网络问题”时能够给出确凿的证据,而不是模糊的猜测?
4. 答案 (Answer)
我们需要从模型原理、核心协议、关键状态和排查工具四个维度来掌握网络通信。
4.1 模型原理:OSI vs TCP/IP
虽然教科书上常讲 OSI 七层模型,但在 Linux 内核和实际排查中,TCP/IP 四层模型更为实用。
| OSI 七层模型 | TCP/IP 四层模型 | 对应协议/工具 | 关注点 (SRE) |
|---|---|---|---|
| 应用层 (Application) | 应用层 | HTTP, DNS, SSH | 状态码, 延迟, 业务逻辑 |
| 表示层 (Presentation) | ^ | SSL/TLS, JSON | 证书过期, 序列化错误 |
| 会话层 (Session) | ^ | RPC Session | 连接池管理 |
| 传输层 (Transport) | 传输层 | TCP, UDP | 端口, 滑动窗口, 拥塞控制 |
| 网络层 (Network) | 网络层 | IP, ICMP, BGP | 路由表, MTU, 防火墙 |
| 数据链路层 (Data Link) | 网络接口层 | ARP, MAC, VLAN | 丢包, CRC 错误 |
| 物理层 (Physical) | ^ | 光纤, 网线 | 物理链路中断 |
4.2 传输层核心:TCP 协议详解
4.2.1 TCP 的生与死
TCP 是互联网的基石,理解其状态机和端口机制是排查连接问题的关键。
4.2.2 TCP端口号机制
TCP端口号是标识网络通信中不同服务或应用的数字,范围从0到65535(2^16-1)。从SRE视角来看,端口号管理直接影响服务的可用性和安全性。
| 端口范围 | 类型 | 用途 | SRE关注点 |
|---|---|---|---|
| 0-1023 | 知名端口 (Well-Known Ports) | 固定分配给常见服务,需管理员权限使用 | 服务占用冲突、未授权访问 |
| 1024-49151 | 注册端口 (Registered Ports) | 分配给程序注册使用,权限要求较宽松 | 应用端口规划、冲突排查 |
| 49152-65535 | 动态/私有端口 (Dynamic/Private Ports) | 操作系统动态分配给客户端进程 | 端口耗尽、连接数限制 |
知名端口示例:
- 80/tcp: HTTP 服务
- 20-21/tcp: FTP 服务(20数据传输,21命令控制)
- 25/tcp: SMTP 邮件服务
- 443/tcp: HTTPS 加密服务
常用注册端口:
- 1433/tcp: SQL Server 数据库
- 1521/tcp: Oracle 数据库
- 3306/tcp: MySQL 数据库
- 11211/tcp/udp: Memcached 缓存
动态端口管理:
# 查看客户端动态端口范围(Linux)
cat /proc/sys/net/ipv4/ip_local_port_range
# 查看非特权用户可使用的起始端口
cat /proc/sys/net/ipv4/ip_unprivileged_port_start
# 查看系统服务端口映射
cat /etc/services
SRE 常见问题:
- 端口耗尽:短连接高并发场景下,客户端动态端口不足导致连接失败
- 端口冲突:同一主机上多个服务尝试使用相同端口
- 权限问题:非特权用户尝试绑定1023以下端口
4.2.3 三次握手 (The Handshake)
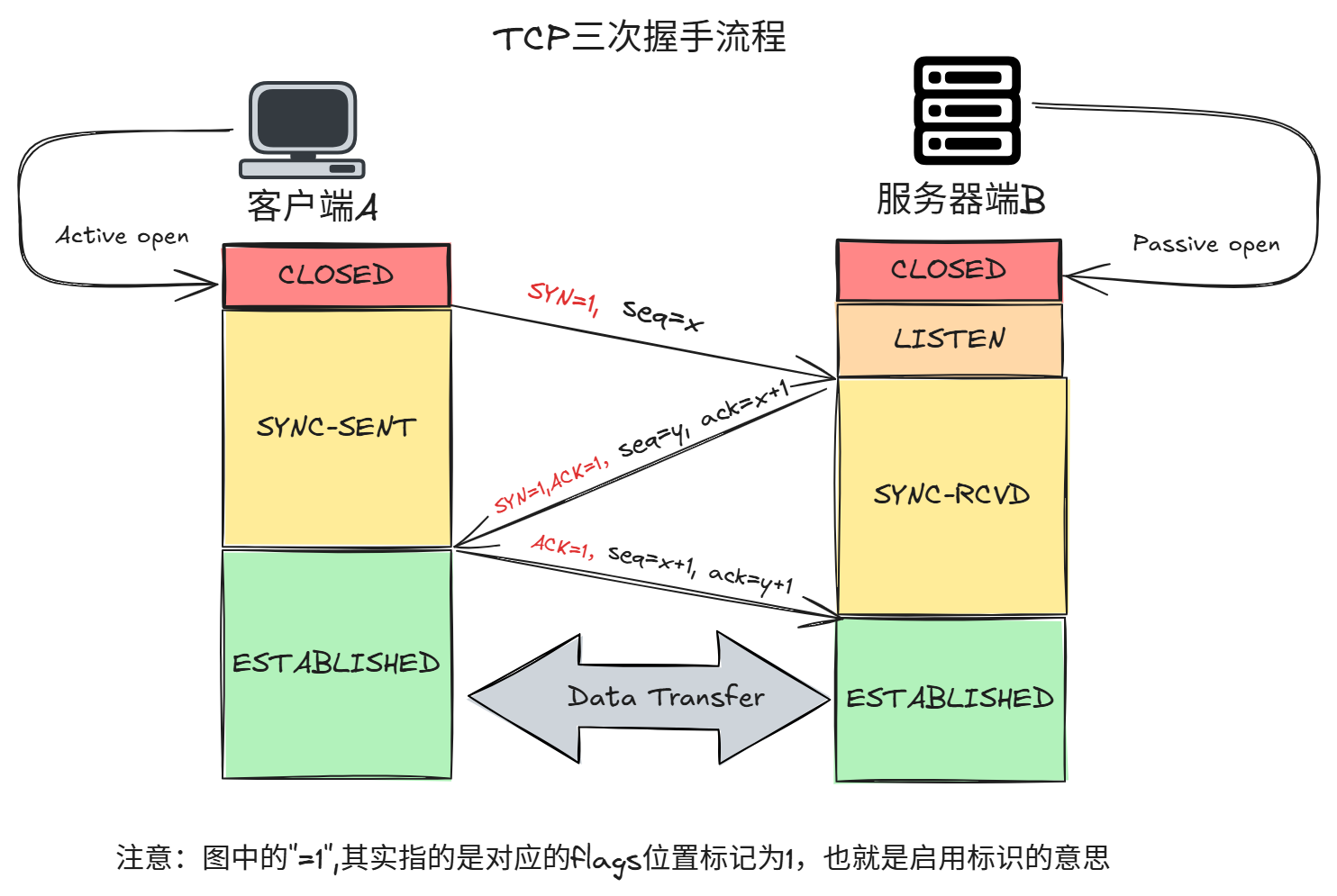
SRE 关注点:
- SYN Flood 攻击:如果 Server 收到大量 SYN 但没收到 ACK,
SYN_RCVD队列会满。- 优化:开启
net.ipv4.tcp_syncookies。
- 优化:开启
- 连接超时:如果 Client 发出 SYN 后无响应,可能是防火墙丢包或 Server 没监听。
4.2.4 TCP确认机制详解
确认号计算规则
TCP的确认号(ack)表示期望接收的下一个序列号,其计算规则如下:
| 场景 | 确认号计算公式 | 示例 |
|---|---|---|
| 三次握手阶段 | ack = 对方的seq + 1 | - 客户端SYN包: seq 734385442- 服务端SYN+ACK包: ack 734385443 = 734385442 + 1 |
| 数据传输阶段 | ack = 对方的seq + 数据长度 | - 客户端GET请求: seq 734385443:734385516,数据长度73- 服务端确认: ack 734385516 = 734385443 + 73- 服务端HTTP响应: seq 4168948237:4168949099,数据长度862- 客户端确认: ack 4168949099 = 4168948237 + 862 |
关键差异说明
- 三次握手阶段:
- SYN包和SYN+ACK包的
length字段为0(不携带应用层数据) - 但SYN标志本身占据一个序列号,所以确认号是
seq + 1 - 这是TCP协议的特殊规定,确保连接建立的可靠性
- SYN包和SYN+ACK包的
- 数据传输阶段:
- 数据包携带实际应用层数据,
length字段大于0 - 确认号是
seq + 数据长度,表示已收到所有数据直到seq + 数据长度 - 1 - 例如:
seq 734385443:734385516表示发送了734385443到734385516(共73字节),所以确认号是734385516(期望接收下一个字节)
- 数据包携带实际应用层数据,
确认机制的作用
- 可靠性保证:确保数据不丢失,接收方必须确认收到的数据
- 流量控制:通过窗口大小字段配合,控制发送方的发送速率
- 序列号同步:确保发送方和接收方的序列号同步,避免数据乱序
常见误区
- ❌ 错误:确认号是”已收到的最后一个序列号”
- ✅ 正确:确认号是”期望接收的下一个序列号”,表示已收到所有序列号小于该值的数据
例如:ack 734385516表示”我已收到所有序列号小于734385516的数据,下一次请发送从734385516开始的数据”
重要说明:tcpdump的序列号显示
- 使用
-S选项时,tcpdump显示绝对序列号,如上面的seq 734385442和ack 734385443 - 不使用
-S选项时,tcpdump默认显示相对序列号,将ISN视为0的偏移值 - 两种显示方式本质相同,相对序列号更易读,绝对序列号更精确
4.2.5 四次挥手 (The Wave) & 状态详解
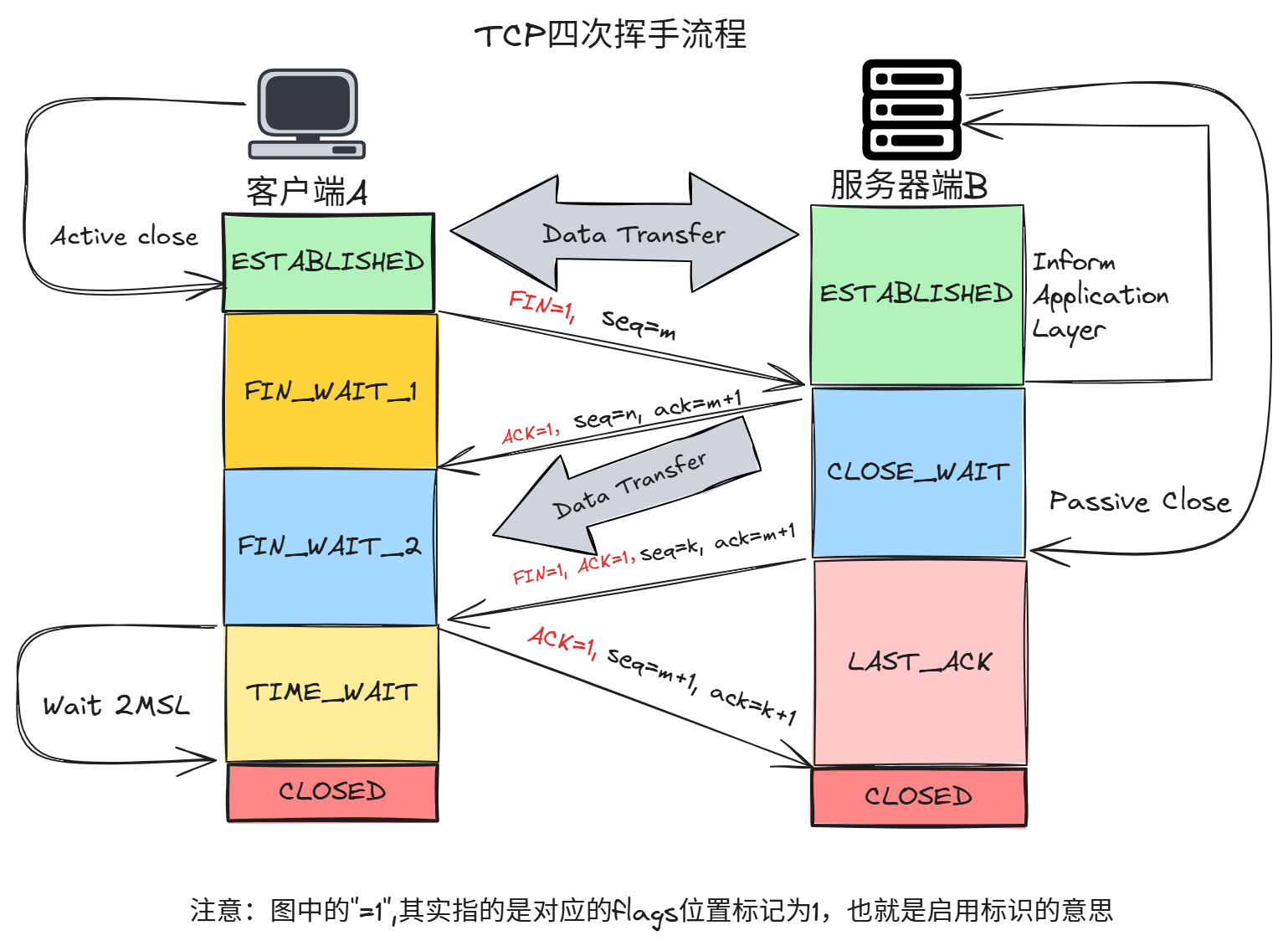
SRE 关注点(高频故障点):
TCP 状态详解
| 状态 | 描述 | 常见角色 |
|---|---|---|
| LISTEN | 套接字正在监听入站连接 | 服务端 |
| CLOSE | 套接字未被使用 | 两端 |
| CLOSE_WAIT | 远程端已关闭,等待本地关闭套接字(半关闭状态) | 服务端(被动关闭方) |
| TIME_WAIT | 主动关闭后等待网络中残余数据包处理 | 客户端(主动关闭方) |
| FIN_WAIT_1 | 已发送FIN,等待ACK | 主动关闭方 |
| FIN_WAIT_2 | 已收到FIN的ACK,等待对方的FIN | 主动关闭方 |
| LAST_ACK | 已关闭套接字,等待最后一个ACK | 被动关闭方 |
| CLOSING | 双方同时关闭,等待所有数据发送完成 | 两端 |
| UNKNOWN | 套接字状态未知 | - |
关闭场景分析
只有服务端的ACK: 客户端发送FIN后,只收到服务端的ACK,会进入FIN_WAIT_2状态。后续收到服务端的FIN时,回应ACK并进入TIME_WAIT状态。
只有服务端的FIN: 客户端收到服务端的FIN时,回应ACK进入CLOSING状态,然后收到服务端的ACK时进入TIME_WAIT状态。
既有服务端的ACK,又有FIN: 客户端同时收到服务端的ACK和FIN,直接进入TIME_WAIT状态。
关键状态深入分析
- CLOSE_WAIT:服务端(被动关闭方)卡在这里,通常是代码 Bug。
- 原因:程序收到了 FIN,但没有调用
close()关闭 socket。 - 后果:占用文件句柄,最终导致服务崩溃。
- 原因:程序收到了 FIN,但没有调用
- TIME_WAIT:客户端(主动关闭方)卡在这里,是正常现象,但过多会有害。
- 作用:确保迷路的包在网络中消失;确保 Server 收到最后的 ACK。
- 持续时间:默认为2MSL(RFC 1122建议值2分钟),但实际由内核参数控制。
- 危害:短连接高并发场景下,耗尽源端口。
- 持续时间控制:由内核参数
net.ipv4.tcp_fin_timeout决定,默认值为60秒(如用户实际环境所示)。 - 查看参数值:
# 方法1:使用sysctl命令 sysctl net.ipv4.tcp_fin_timeout # 输出:net.ipv4.tcp_fin_timeout = 60 # 方法2:直接读取/proc文件 cat /proc/sys/net/ipv4/tcp_fin_timeout # 输出:60
4.2.6 TCP 内核参数调整
以下是常见的TCP内核参数调整建议,可在/etc/sysctl.conf文件中配置:
# 查看当前配置
cat /etc/sysctl.conf
# 应用新配置
sysctl -p
| 参数 | 描述 | 默认值 | 建议值 | SRE生产实践案例 |
|---|---|---|---|---|
| net.ipv4.tcp_fin_timeout | 套接字保持在FIN-WAIT-2状态的时间 | 60秒 | 15-60秒 | 案例:电商平台大促期间,Web服务器处理10万+ QPS短连接,将该值从60秒调整为30秒,TIME-WAIT连接数从8万降至3万,释放了大量系统资源。 注意:过低(<15秒)可能导致网络延迟高时连接异常。 |
| net.ipv4.tcp_tw_reuse | 允许将TIME-WAIT套接字重新用于新连接 | 0(关闭) | 1(开启) | 案例:API网关服务器需要同时向200+微服务发起连接,开启该参数后,TIME-WAIT连接复用率达到60%,源端口耗尽问题彻底解决。 适用场景:高并发outbound连接(微服务调用、CDN回源)。 |
| net.ipv4.tcp_tw_recycle | 开启TIME-WAIT套接字快速回收(新内核已废弃) | 0(关闭) | 0(不建议开启) | 案例:某负载均衡器开启该参数后,NAT环境下的客户端出现”connection reset by peer”错误,关闭后恢复正常。 原理:该参数基于时间戳判断连接有效性,在NAT环境下会导致不同客户端的连接被错误回收。 |
| net.ipv4.tcp_syncookies | 开启SYN Cookies防范SYN攻击 | 1(开启) | 1 | 案例:某游戏服务器遭受SYN洪水攻击,syn_backlog队列满导致连接拒绝,开启该参数后,服务器能正常处理合法连接,同时抵御攻击。 注意:会轻微影响TCP性能,但在公网环境下是必要的安全措施。 |
| net.ipv4.tcp_keepalive_time | TCP发送keepalive消息的频度 | 7200秒(2小时) | 600秒(10分钟) | 案例:数据库连接池中的连接因网络波动被中间设备断开,应用层未感知导致大量”broken pipe”错误,将该值从2小时调整为10分钟后,失效连接能被及时检测并重建。 适用场景:长连接应用(数据库、WebSocket、消息队列)。 |
| net.ipv4.ip_local_port_range | 向外连接的端口范围 | 32768 61000 | 2000 65000 | 案例:爬虫服务器需要同时发起10万+并发连接,默认端口范围仅28233个可用端口,调整为2000-65000后,可用端口数达到63001个,解决了端口耗尽问题。 |
| net.ipv4.tcp_max_syn_backlog | SYN队列长度(半连接队列) | 1024 | 16384 | 案例:直播平台秒杀活动中,服务器每秒收到5万+ SYN请求,默认队列长度导致大量连接被丢弃,调整为16384后,连接成功率从85%提升至99.5%。 配合:需同时调整 somaxconn参数。 |
| net.ipv4.tcp_max_tw_buckets | 系统同时保持TIME_WAIT套接字的最大数量 | 180000 | 36000 | 案例:某高并发Web服务器TIME_WAIT连接数经常超过10万,导致系统内存占用过高,调整为36000后,超过阈值的TIME_WAIT连接会被主动回收,系统稳定性提升。 注意:该值不宜过小,否则会导致连接重置。 |
| net.ipv4.route.gc_timeout | 路由缓存过期时间 | - | 100 | 案例:云环境中虚拟机频繁创建销毁,路由表变化频繁,调整该值从默认值到100秒后,路由缓存更新更快,减少了”no route to host”错误。 |
| net.ipv4.tcp_syn_retries | 内核放弃建立连接前发送SYN包的数量 | 6 | 1 | 案例:微服务架构中,服务间调用超时要求1秒,将该值从6(总超时~1分钟)调整为1(总超时~1秒)后,故障服务能被快速发现,熔断机制及时触发。 适用场景:对延迟敏感的分布式系统。 |
| net.ipv4.tcp_synack_retries | 内核放弃连接前发送SYN+ACK包的数量 | 5 | 1 | 案例:公网服务器收到大量无效SYN请求,发送SYN+ACK重试消耗了大量带宽,调整为1后,无效连接资源消耗降低80%。 安全建议:公网服务器建议设置为1-2次。 |
| net.ipv4.tcp_max_orphans | 未关联到用户文件句柄的TCP套接字最大数量 | 8192 | 16384 | 案例:某Web服务器遭受DDoS攻击,大量半开连接导致orphan套接字激增,超过默认值后内核开始丢弃连接,调整为16384后,系统能更好地抵御攻击。 原理:防止恶意攻击消耗系统资源。 |
| net.core.somaxconn | 全连接队列长度 | 128 | 16384 | 案例:Nginx服务器监听80端口,并发连接数超过128时,ss -s显示”SYNs to LISTEN sockets dropped”,调整为16384并修改Nginx的worker_connections后,连接丢弃问题消失。注意:需与应用层配置(如Nginx、Tomcat的max connections)配合调整。 |
| net.core.netdev_max_backlog | 网络接口接收数据包的最大队列长度 | 1000 | 16384 | 案例:视频流服务器处理40Gbps流量时,网络接口队列经常满导致数据包丢失,调整为16384后,丢包率从0.5%降至0.01%。 适用场景:高流量服务器(视频、CDN、大文件传输)。 |
生产环境优化策略(SRE实战总结)
1. 高并发Web服务器:
- 开启
tcp_tw_reuse,调整tcp_fin_timeout=30 - 扩大
somaxconn=16384和tcp_max_syn_backlog=16384 - 开启
tcp_syncookies=1防范攻击
2. 微服务API网关:
- 开启
tcp_tw_reuse=1,调整ip_local_port_range=2000 65000 - 缩短
tcp_syn_retries=1和tcp_synack_retries=1 - 调整
tcp_keepalive_time=600及时检测失效连接
3. 数据库服务器:
- 调整
tcp_keepalive_time=300(5分钟) - 关闭
tcp_tw_reuse(数据库连接要求高可靠性) - 保持
tcp_syncookies=1开启
4. 负载均衡器:
- 开启
tcp_tw_reuse=1,调整tcp_fin_timeout=20 - 关闭
tcp_tw_recycle=0(NAT环境必备) - 扩大
netdev_max_backlog=16384处理高流量
SRE调优注意事项
- 渐进式调整:每次只修改1-2个参数,观察24小时后再调整其他参数
- 监控先行:调整前开启TCP连接监控(
ss -s、netstat -s、Prometheus) - 差异化配置:不同角色服务器(Web、DB、网关)使用不同的参数配置
- 内核版本兼容:部分参数在新内核中已废弃(如
tcp_tw_recycle) - 应用层配合:TCP参数需与应用层配置(如Nginx的
worker_connections)协同调优 - 灰度验证:先在测试环境验证,再小规模灰度,最后全量推广
核心调优思路:TCP参数调优的本质是在连接可靠性和系统资源利用率之间寻找平衡,SRE需要根据业务场景、流量模型和硬件资源制定最优配置。
4.2.7 TCP连接实战:使用netcat模拟TCP通信
netcat (简称 nc) 是 SRE 常用的网络工具,可以用来模拟 TCP/UDP 连接,测试端口连通性,甚至作为简单的服务器使用。
安装netcat
# Rocky/CentOS 系统
yum install -y nc
# Ubuntu/Debian 系统
apt install -y netcat-openbsd
模拟TCP连接过程
1. 服务端监听端口 在 Rocky 系统 (10.0.0.12) 上启动一个 TCP 监听服务:
# 监听 222 端口
nc -l 222
2. 客户端发起连接 在 Ubuntu 系统 (10.0.0.13) 上连接到服务端:
# 连接到 10.0.0.12 的 222 端口
nc 10.0.0.12 222
3. 双向通信 连接建立后,双方可以互相发送数据:
# 在客户端输入
123
333
# 服务端会收到同样的数据,并可以回复
4. 查看TCP连接状态 在服务端使用 ss 命令查看 TCP 连接状态:
ss -tn
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 10.0.0.12:222 10.0.0.13:51760 # 已建立的TCP连接
5. 查看监听状态的TCP端口
# 使用 ss 查看所有监听状态的TCP端口
root@rocky9 ~]# ss -tnl
root@ubuntu24:~# ss -tnl
SRE 实战意义:
- 快速验证端口连通性:不需要依赖具体服务,直接测试TCP连接
- 模拟服务行为:在服务开发完成前,可以用netcat模拟服务响应
- 测试防火墙规则:验证防火墙是否正确放行特定端口的流量
- 调试网络问题:通过简单的连接测试,定位是网络问题还是服务问题
4.2.8 TCP连接实战:实际三次握手和四次挥手分析
案例背景
用户在Rocky Linux主机(10.0.0.12)上执行curl 10.0.0.13访问Ubuntu主机(10.0.0.13)上的Nginx服务,同时在Ubuntu主机上使用tcpdump -S -i eth0 tcp port 80捕获了完整的TCP连接过程(使用-S选项显示绝对序列号)。
捕获结果分析
1. 三次握手过程
# 使用tcpdump -S选项捕获的完整三次握手(显示绝对序列号)
# 1. Client(10.0.0.12)发送SYN包,发起连接请求
10:34:35.592313 IP 10.0.0.12.35300 > ubuntu24.http: Flags [S], seq 734385442, win 64240, options [mss 1460,sackOK,TS val 3595154787 ecr 0,nop,wscale 7], length 0
# 标志位:[S] = SYN (同步序列编号)
# 含义:Client请求建立连接,初始序列号(ISN)=734385442
# 2. Server(ubuntu24)发送SYN+ACK包,同意建立连接
10:34:35.592336 IP ubuntu24.http > 10.0.0.12.35300: Flags [S.], seq 4168948236, ack 734385443, win 65160, options [mss 1460,sackOK,TS val 3255908001 ecr 3595154787,nop,wscale 7], length 0
# 标志位:[S.] = SYN+ACK (同步+确认)
# 含义:Server同意连接,Server的ISN=4168948236,确认号=Client的ISN+1
# 3. Client发送ACK包,连接建立完成
10:34:35.592868 IP 10.0.0.12.35300 > ubuntu24.http: Flags [.], ack 4168948237, win 502, options [nop,nop,TS val 3595154788 ecr 3255908001], length 0
# 标志位:[.] = ACK (确认)
# 含义:Client确认收到Server的SYN+ACK,确认号=Server的ISN+1
# 此时TCP连接建立完成,进入ESTABLISHED状态
TCP包各字段详细解释
| 字段 | 含义 | 详细解释 |
|---|---|---|
| IP 10.0.0.12.35300 > ubuntu24.http | 源IP:端口 > 目标IP:端口 | 表示从10.0.0.12的35300端口发送到ubuntu24主机的80端口(HTTP服务) |
| Flags [S] | TCP标志位 | [S]表示SYN(同步)标志,用于发起TCP连接 |
| Flags [S.] | TCP标志位 | [S.]表示SYN+ACK(同步+确认)标志,用于同意建立TCP连接 |
| Flags [.] | TCP标志位 | [.]表示ACK(确认)标志,用于确认收到数据 |
| Flags [P.] | TCP标志位 | [P.]表示PSH+ACK(推送+确认)标志,用于推送数据到应用层 |
| seq 734385442 | 初始序列号(ISN) | TCP连接的初始序列号,由客户端随机生成,用于确保连接的唯一性和安全性 |
| seq 734385443:734385516 | 数据范围 | 表示此TCP段包含的数据范围,从seq 734385443到734385516(含) |
| ack 734385443 | 确认号 | 表示期望接收的下一个序列号,确认已收到所有序列号小于该值的数据 |
| win 64240 | 初始通告窗口大小 | 连接建立时客户端发送的原始通告窗口大小,未经过窗口缩放因子调整 |
| win 502 | 通告窗口值 | 经过窗口缩放协商后,TCP头部中实际携带的窗口值,需要结合wscale计算实际窗口大小 |
| options | TCP选项字段 | TCP头部的扩展选项,包含多种控制信息 |
| mss 1460 | 最大段大小(Max Segment Size) | 表示客户端能够接收的最大TCP段大小为1460字节,通常等于MTU(1500)减去TCP头部(20)和IP头部(20) |
| sackOK | 选择性确认支持 | 表示客户端支持SACK(Selective Acknowledgment)选项,允许接收方确认不连续的数据段,提高TCP重传效率 |
| TS val 3595154787 ecr 0 | 时间戳选项 | - TS val: 发送方的时间戳值,用于RTT(往返时间)计算和防止序列号回绕- ecr: 时间戳回显应答,此处为0表示这是连接建立的第一个包 |
| TS val 3255908001 ecr 3595154787 | 时间戳选项(应答) | - TS val: 服务端的时间戳值- ecr: 回显客户端的时间戳值,用于RTT计算 |
| nop | 无操作 | 用于填充TCP选项字段,确保选项字段总长度为4字节的整数倍,便于协议解析和高效处理 多个nop出现的原因:TCP选项字段必须是4字节对齐的,当其他选项的总长度不是4的倍数时,会插入多个nop来填充 示例分析: options [nop,nop,TS val 3595154788 ecr 3255908002]- TS选项(时间戳)长度为10字节 - 加上2个nop(各1字节),总长度=10+2=12字节,正好是4的倍数 - 所以需要两个nop来确保4字节对齐 |
| wscale 7 | 窗口缩放因子 | 表示窗口缩放比例为2^7=128倍,用于扩展TCP接收窗口大小,支持更大的带宽利用率 计算公式:实际接收窗口大小 = 通告窗口值 × 2^wscale 示例: - 客户端SYN包: win 64240, wscale 7 → 实际窗口=64240×128=8,222,720字节- ACK包中的 win 502 → 实际窗口=502×128=64,256字节(接近初始窗口大小) |
| length 0 | 数据长度 | 表示此TCP段中没有携带应用层数据,仅用于控制目的 |
| length 73 | 数据长度 | 表示此TCP段中携带的应用层数据长度为73字节 |
窗口缩放机制详解
TCP头部中的窗口字段只有16位,最大只能表示65535字节的窗口大小,这在高速网络环境下会成为瓶颈。为了解决这个问题,TCP引入了窗口缩放(Window Scaling)选项,通过协商一个缩放因子来扩展实际窗口大小。
窗口缩放的工作原理:
- 协商阶段:在三次握手的SYN包和SYN+ACK包中,双方通过
wscale选项协商窗口缩放因子 - 存储阶段:协商完成后,双方会存储对方的窗口缩放因子
- 传输阶段:在后续的数据传输中,TCP头部的
win字段携带的是”通告窗口值”,需要结合之前协商的缩放因子计算出实际接收窗口大小 - 计算阶段:实际接收窗口大小 = 通告窗口值 × 2^缩放因子
为什么会有win 502?
- TCP头部的窗口字段只有16位,最大能表示65535字节
- 当需要表示更大的窗口时,系统会使用缩放因子
- 在示例中,客户端和服务端协商的
wscale 7意味着缩放比例为128倍 - 当实际窗口大小为64,256字节时,TCP头部中存储的通告窗口值为:64,256 ÷ 128 = 502
- 所以在抓包中看到的
win 502,经过计算后实际窗口大小是502 × 128 = 64,256字节
窗口缩放的特点:
- 窗口缩放因子只在连接建立时协商,连接期间保持不变
- 缩放因子的范围是0-14(2^14=16384倍),实际窗口大小最大可达65535×16384≈1GB
- 窗口缩放是单向的,客户端和服务端可以协商不同的缩放因子
- 只有在连接建立的SYN包中才能设置
wscale选项,其他包中该选项无效
窗口值变化的原因:
在TCP连接过程中,win值会动态变化,主要受以下因素影响:
- 应用层消费速度:如果应用层处理数据慢,接收缓冲区会被填满,窗口值会减小
- 网络状况:网络拥塞时,TCP会通过调整窗口大小进行流量控制
- 系统资源:系统内存不足时,会减少TCP接收缓冲区大小,导致窗口值减小
- 初始窗口策略:不同操作系统有不同的初始窗口策略(如RFC 6928推荐初始窗口为10个MSS)
2. 数据传输过程
# Client发送HTTP GET请求
10:34:35.592869 IP 10.0.0.12.35300 > ubuntu24.http: Flags [P.], seq 734385443:734385516, ack 4168948237, win 502, options [nop,nop,TS val 3595154788 ecr 3255908001], length 73: HTTP: GET / HTTP/1.1
# 标志位:[P.] = PSH+ACK (推送+确认)
# 含义:Client发送HTTP请求数据,PSH标志要求立即推送数据到应用层
# 数据范围:seq 734385443-734385516(共73字节,即GET请求内容)
# Server确认收到GET请求
10:34:35.592903 IP ubuntu24.http > 10.0.0.12.35300: Flags [.], ack 734385516, win 509, options [nop,nop,TS val 3255908002 ecr 3595154788], length 0
# 标志位:[.] = ACK (确认)
# 含义:Server已收到Client的GET请求,ack=734385516表示期望接收下一个字节
# Server发送HTTP响应数据
10:34:35.593105 IP ubuntu24.http > 10.0.0.12.35300: Flags [P.], seq 4168948237:4168949099, ack 734385516, win 509, options [nop,nop,TS val 3255908002 ecr 3595154788], length 862: HTTP: HTTP/1.1 200 OK
# 标志位:[P.] = PSH+ACK (推送+确认)
# 含义:Server发送HTTP响应数据,包含状态码200 OK
# 数据范围:seq 4168948237-4168949099(共862字节,即HTTP响应内容)
# Client确认收到HTTP响应
10:34:35.593249 IP 10.0.0.12.35300 > ubuntu24.http: Flags [.], ack 4168949099, win 496, options [nop,nop,TS val 3595154788 ecr 3255908002], length 0
# 标志位:[.] = ACK (确认)
# 含义:Client已收到Server的完整响应,ack=4168949099表示期望接收下一个字节
3. 四次挥手过程
# Client发起关闭连接请求
10:34:35.594148 IP 10.0.0.12.35300 > ubuntu24.http: Flags [F.], seq 734385516, ack 4168949099, win 496, options [nop,nop,TS val 3595154789 ecr 3255908002], length 0
# 标志位:[F.] = FIN+ACK (结束+确认)
# 含义:Client完成数据发送,请求关闭连接
# Server确认收到FIN请求 并 同时发送自己的FIN请求
10:34:35.594354 IP ubuntu24.http > 10.0.0.12.35300: Flags [F.], seq 4168949099, ack 734385517, win 509, options [nop,nop,TS val 3255908003 ecr 3595154789], length 0
# 标志位:[F.] = FIN+ACK (结束+确认)
# 含义:Server确认收到Client的关闭请求,同时发送自己的FIN请求
# Client确认收到Server的FIN请求
10:34:35.594554 IP 10.0.0.12.35300 > ubuntu24.http: Flags [.], ack 4168949100, win 496, options [nop,nop,TS val 3595154790 ecr 3255908003], length 0
# 标志位:[.] = ACK (确认)
# 含义:Client确认收到Server的关闭请求,Server收到此ACK后连接关闭
# 此时Client进入TIME_WAIT状态,等待2MSL(最大段生存期)时间
四次挥手的优化:FIN+ACK合并机制
在传统的TCP四次挥手中,关闭连接的过程应该是:
- 第一次挥手:Client发送FIN请求关闭连接
- 第二次挥手:Server发送ACK确认收到FIN
- 第三次挥手:Server发送FIN请求关闭反向连接
- 第四次挥手:Client发送ACK确认收到FIN
但在实际抓包中,我们经常看到服务器将第二次和第三次挥手合并为一个FIN+ACK包,这是TCP协议的一种优化机制。
为什么会出现FIN+ACK合并?
当服务器收到客户端的FIN请求时,如果服务器:
- 已经没有数据要发送给客户端
- 准备关闭连接
- 不需要额外的处理时间
那么服务器可以选择将ACK和FIN合并发送,减少一次网络往返,提高关闭连接的效率。
结合抓包示例分析:
在用户提供的抓包中:
- Client发送FIN:
Flags [F.], seq 734385516表示客户端请求关闭连接 - Server回复FIN+ACK:
Flags [F.], seq 4168949099, ack 734385517ack 734385517:表示Server确认收到Client的FIN(完成第二次挥手)seq 4168949099和Flags [F]:表示Server同时发送FIN请求关闭反向连接(完成第三次挥手)
FIN+ACK合并的条件:
- 服务器无数据待发送:服务器的发送缓冲区已空,没有后续数据要发送给客户端
- 连接状态允许:服务器已经准备好关闭连接,不需要额外的处理时间
- TCP状态转换:服务器从
ESTABLISHED状态直接进入LAST_ACK状态,而不是先进入CLOSE_WAIT状态(跳过了等待应用层关闭的阶段) - 应用层配合:应用层程序(如Nginx)在处理完请求后立即调用close()或shutdown()关闭连接
正常四次挥手与合并挥手的对比:
| 阶段 | 正常四次挥手 | FIN+ACK合并的三次挥手 |
|---|---|---|
| 1 | Client → FIN | Client → FIN |
| 2 | Server → ACK | (合并) |
| 3 | Server → FIN | Server → FIN+ACK |
| 4 | Client → ACK | Client → ACK |
| 网络往返次数 | 4次 | 3次 |
| 适用场景 | 服务器需要处理完剩余数据后再关闭 | 服务器已无数据发送,可立即关闭 |
SRE关注点:
- 连接关闭效率:FIN+ACK合并可以减少一次网络往返,提高连接关闭效率,特别适合短连接场景
- 状态转换监控:通过观察TCP状态转换(如
CLOSE_WAIT状态的时长),可以判断应用层程序是否存在资源泄漏 - 异常情况排查:如果服务器长时间处于
CLOSE_WAIT状态,可能表示应用层程序没有正确关闭连接 - 性能优化:对于高并发服务,合理的连接关闭策略可以减少TIME_WAIT状态的数量,降低系统资源消耗
为什么客户端不会合并挥手?
客户端通常不会合并挥手,因为客户端在发送FIN后,需要等待服务器的确认和服务器的FIN请求,这两个事件的时间点通常不重合。而且客户端作为主动关闭方,需要进入TIME_WAIT状态,这是TCP协议的设计要求,用于确保网络中残留的数据包被正确处理。
4. 对应的curl命令结果
0 ✓ 10:34:35 root@rocky9.6-12,10.0.0.12:~ # curl 10.0.0.13
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
0 ✓ 10:34:35 root@rocky9.6-12,10.0.0.12:~ #
# 这是curl命令获取到的Nginx默认页面,对应TCP连接中的HTTP响应数据
SRE关注点:
- 连接建立时间:三次握手耗时约0.555ms(从SYN到ACK的时间差:10:34:35.592313 → 10:34:35.592868),说明网络延迟很低
- 数据传输效率:HTTP请求(73字节)和响应(862字节)都在单个TCP段中传输,没有分片
- 连接关闭方式:使用标准的四次挥手关闭连接,没有出现异常状态
- TCP参数:双方都使用了MSS 1460、SACK和窗口缩放等优化参数
- TIME_WAIT状态:连接关闭后客户端进入TIME_WAIT状态,符合TCP协议规范
分析思路:
- 首先确认TCP连接是否成功建立(三次握手是否完整)
- 检查数据传输是否正常(PSH标志位表示数据推送,ACK确认号递增正常)
- 验证连接关闭是否正常(四次挥手是否完整,序列号和确认号匹配)
- 关注TCP标志位和序列号的变化,理解连接状态的转换
- 结合应用层数据(HTTP请求/响应),理解端到端的通信过程
- 分析TCP参数(MSS、窗口大小、TS选项)对性能的影响
4.3 传输层轻骑兵:UDP 协议详解
与 TCP 相比,UDP(User Datagram Protocol)是一种无连接、不可靠、面向报文的传输层协议。它提供了简单的传输服务,不保证数据的可靠传输和顺序到达,但具有较低的延迟和开销。
4.3.1 UDP 报文结构
UDP 报文由首部和数据两部分组成,其中首部固定为 8 个字节,包含以下四个字段:
| 字段名 | 长度(位) | 描述 |
|---|---|---|
| 源端口(Source Port) | 16 | 在要求对方回信时选用,不要求时可使用全 0 |
| 目的端口(Destination Port) | 16 | 在终点交付报文时必须使用 |
| 长度(Length) | 16 | UDP 用户数据报的长度,包括首部和数据,最小值为 8(仅有首部) |
| 检验和(Checksum) | 16 | 用于检测 UDP 用户数据报在传输中是否出错,出错则丢弃 |
UDP 首部与伪首部的区别
为了确保 UDP 数据报的正确性,UDP 使用了一个特殊的伪首部(Pseudo Header)进行校验。伪首部与 UDP 实际首部有以下主要区别:
| 特性 | UDP 实际首部 | 伪首部(Pseudo Header) |
|---|---|---|
| 组成 | 源端口、目的端口、长度、检验和 | 源 IP 地址(32位)、目的 IP 地址(32位)、保留字段(8位)、协议字段(8位)、UDP 数据报总长度(16位) |
| 长度 | 固定 8 字节 | 固定 12 字节 |
| 传递方式 | 实际包含在 UDP 数据报中,在网络中传输 | 仅在发送端计算校验和时临时构建,不实际传输,也不向下或向上传递 |
| 作用范围 | 标识应用层服务(端口号)和数据长度 | 确保 UDP 数据报发送到正确的主机和协议类型 |
| 主要作用 | 提供基本的传输层功能 | 仅用于校验套接字的正确性(确保数据报从正确的源 IP 发送到正确的目的 IP,使用正确的协议) |
| 生命周期 | 与 UDP 数据报相同,从发送到接收 | 仅存在于校验和计算过程中,计算完成后立即丢弃 |
伪首部校验的工作原理:
- 发送端在计算 UDP 校验和时,临时构建伪首部
- 将伪首部与 UDP 实际首部、数据部分组合成一个完整的校验数据
- 对组合后的数据进行校验和计算
- 将计算得到的校验和填入 UDP 实际首部的检验和字段
- 接收端使用相同的方法重新计算校验和,若与收到的检验和字段值不一致,则丢弃该数据报
4.3.2 UDP IP 寻址原理
有读者可能会问:伪首部仅在发送端计算校验和时临时构建,不实际传输,那 UDP 仅靠首部的端口如何能确认要发送的目的 IP 地址?
这涉及到 UDP 在网络协议栈中的工作原理:
应用层提供完整寻址信息:当应用程序(如 DNS 客户端)使用 UDP 发送数据时,会同时提供目的 IP 地址和目的端口号给操作系统。
- 协议栈分层处理:
- 应用层:准备要发送的数据,并指定目的 IP 地址和端口号
- 传输层(UDP):只负责处理端口号,添加 UDP 首部(包含源端口和目的端口)
- 网络层(IP):负责处理 IP 地址,添加 IP 首部(包含源 IP 地址和目的 IP 地址)
- 数据链路层:添加 MAC 地址,负责局域网内的寻址
UDP 不负责 IP 寻址:UDP 作为传输层协议,其核心职责是端口复用与分用,即将数据交付到正确的应用程序。IP 地址的处理和路由是网络层(IP 协议)的职责。
- 完整的数据包封装过程:
应用数据 +---------------+ | UDP 首部 | (仅包含端口号) +---------------+ | IP 首部 | (包含源 IP 和目的 IP) +---------------+ | MAC 首部 | (包含源 MAC 和目的 MAC) +---------------+ 伪首部的校验作用:伪首部的作用只是在计算校验和时,额外验证数据报是否发送到了正确的主机(IP 地址)和协议类型,防止数据包在传输过程中被错误路由到其他主机的相同端口。
- 接收端的处理流程:
- 网络层(IP)接收到数据包后,根据 IP 首部的目的 IP 地址判断是否是发给本机
- 如果是,IP 层会剥离 IP 首部,将 UDP 数据包传递给传输层
- UDP 层根据 UDP 首部的目的端口号,将数据交付给对应的应用程序
- 应用程序通过套接字(Socket)获取完整的发送方信息(IP 地址和端口号)
简而言之,UDP 数据包的 IP 寻址是由 IP 层完成的,UDP 本身只负责端口级别的寻址。伪首部只是校验机制的一部分,确保数据包在端到端传输过程中的完整性和正确性。
4.3.3 SRE 视角下的 UDP 使用场景
UDP 虽然是不可靠的传输协议,但在特定场景下具有 TCP 无法替代的优势。从 SRE 的角度来看,UDP 主要适用于以下场景:
1. 实时音视频传输
- 典型应用:VoIP 电话、视频会议、直播流
- SRE 关注点:
- 低延迟比可靠性更重要,少量丢包可通过应用层纠错机制处理
- 避免 TCP 的重传机制导致的延迟累积
- 关注 jitter(抖动)和 packet loss rate(丢包率)指标
- 示例:WebRTC 技术栈大量使用 UDP 进行媒体流传输
2. 游戏数据传输
- 典型应用:多人在线游戏、实时竞技游戏
- SRE 关注点:
- 游戏状态更新需要低延迟,TCP 的重传会导致游戏卡顿
- 游戏客户端可以容忍少量丢包,通过预测算法恢复
- 关注 UDP 包的到达顺序,应用层可实现轻量级的顺序保证
- 示例:《英雄联盟》、《绝地求生》等游戏使用自定义 UDP 协议
3. DNS 查询
- 典型应用:域名解析请求
- SRE 关注点:
- DNS 查询数据包小(通常小于 512 字节),UDP 开销低
- DNS 协议本身具有重试机制,弥补 UDP 不可靠的缺点
- 关注 DNS 服务器的 UDP 端口 53 负载
- 排查案例:DNS 放大攻击(利用 UDP 无连接特性发送大量伪造请求)
4. 网络诊断工具
- 典型应用:ping、traceroute、mtr
- SRE 关注点:
- ping 使用 ICMP(基于 IP),但 traceroute 在某些模式下使用 UDP
- UDP 可以用于测试特定端口的可达性(如
nc -u -z -v example.com 53) - 关注工具输出的延迟、丢包率等指标
- 示例:使用
traceroute -U example.com 53测试 DNS 路径
5. 服务发现与健康检查
- 典型应用:Consul、etcd、ZooKeeper 的健康检查
- SRE 关注点:
- 健康检查通常是短平快的请求,UDP 开销低
- 允许一定的丢包,通过多次重试提高可靠性
- 关注服务注册中心的 UDP 端口负载
- 示例:Consul 支持 UDP 健康检查,可配置超时和重试次数
6. 大规模数据分发
- 典型应用:流媒体分发、软件更新、日志收集
- SRE 关注点:
- UDP 支持组播(Multicast)和广播(Broadcast),适合一对多数据分发
- 降低服务器负载,提高分发效率
- 应用层实现可靠性保证(如 P2P 协议)
- 示例:BitTorrent 协议使用 UDP 进行 tracker 通信
4.3.4 SRE 常见 UDP 问题及排查
1. UDP 丢包问题
- 排查步骤:
- 使用
ping或mtr检查网络连通性和丢包率 - 使用
tcpdump或wireshark捕获 UDP 包,分析丢包模式 - 检查系统 UDP 缓冲区设置:
# 查看 UDP 接收缓冲区默认值 sysctl net.core.rmem_default # 查看 UDP 接收缓冲区最大值 sysctl net.core.rmem_max - 检查应用程序是否存在处理瓶颈
- 使用
2. UDP 端口占用
- 排查命令:
# 查看 UDP 端口监听情况 ss -lnup # 或使用 netstat netstat -lnup # 查找占用特定 UDP 端口的进程 lsof -i :53
3. UDP 洪水攻击防护
- 防护措施:
- 配置防火墙限制 UDP 流量速率
- 使用
iptables设置 UDP 连接限制:iptables -A INPUT -p udp --dport 53 -m limit --limit 100/s --limit-burst 200 -j ACCEPT iptables -A INPUT -p udp --dport 53 -j DROP - 部署 DDoS 防护服务
- 关注
netstat -s输出中的 UDP 相关统计信息
4.3.5 UDP 与 TCP 的对比(SRE 视角)
| 特性 | TCP | UDP | SRE 决策参考 |
|---|---|---|---|
| 连接性 | 面向连接 | 无连接 | TCP 适合需要可靠传输的场景,UDP 适合低延迟场景 |
| 可靠性 | 可靠(有序、无丢包、无重复) | 不可靠(可能丢包、乱序、重复) | 根据业务对可靠性的要求选择 |
| 延迟 | 较高(握手、重传、拥塞控制) | 较低(无握手、无重传) | 实时应用优先选择 UDP |
| 吞吐量 | 适合大数据量传输 | 适合小数据包传输 | 数据量大且对可靠性要求高时选择 TCP |
| 资源消耗 | 较高(连接状态管理、缓冲区管理) | 较低(无连接状态) | 高并发场景下 UDP 资源消耗更低 |
| 适用场景 | Web 服务、文件传输、API 调用 | 音视频、游戏、DNS、健康检查 | 根据具体业务场景选择合适的协议 |
传输层核心总结
传输层是连接应用层和网络层的关键桥梁,TCP 和 UDP 作为传输层的两大核心协议,各有其适用场景。从 SRE 的角度来看:
- TCP 适合:对可靠性要求高、数据量大、允许一定延迟的场景,如 Web 服务、数据库连接、文件传输等。
- UDP 适合:对延迟敏感、数据量小、可以容忍少量丢包的场景,如音视频传输、游戏、DNS 查询等。
- 协议选择原则:根据业务需求平衡可靠性、延迟、吞吐量和资源消耗。
- SRE 核心技能:掌握 TCP 和 UDP 的工作原理,能够使用抓包工具分析传输层问题,理解内核参数对传输层性能的影响。
4.4 应用层核心:DNS 与 HTTP
DNS:网络世界的导航仪
DNS 解析流程通常是:本地 hosts -> 本地 DNS 缓存 -> 递归 DNS 服务器 -> 根/顶级/权威 DNS 服务器。
常见问题:
- 解析慢:递归 DNS 响应慢,或者 UDP 包被限速/丢弃。
- 解析错:DNS 劫持或缓存污染。
- ndots 陷阱:在 Kubernetes 中,默认
ndots:5会导致大量无效的 DNS 查询(如google.com.default.svc.cluster.local),增加延迟。
DNS 搜索域配置:简化域名访问
DNS 搜索域(Search Domain)是一种方便的配置,可以让用户在访问域名时省略默认的域名后缀,系统会自动补全并尝试解析。
配置示例:
# 查看 /etc/resolv.conf 文件
cat /etc/resolv.conf
# Generated by NetworkManager
search clockwingsoar.cyou
nameserver 223.5.5.5
nameserver 223.6.6.6
使用效果: 当配置了 search clockwingsoar.cyou 后,用户可以直接使用主机名访问,系统会自动补全域名后缀:
# 直接 ping www,系统会自动尝试解析为 www.clockwingsoar.cyou
ping -c1 www
PING www.clockwingsoar.cyou (106.15.38.115) 56(84) 字节的数据。
64 字节,来自 106.15.38.115 (106.15.38.115): icmp_seq=1 ttl=128 时间=15.5 毫秒
# 多次 ping 测试,均能成功解析
ping -c5 www
PING www.clockwingsoar.cyou (106.15.38.115) 56(84) 字节的数据。
64 字节,来自 106.15.38.115 (106.15.38.115): icmp_seq=1 ttl=128 时间=18.3 毫秒
64 字节,来自 106.15.38.115 (106.15.38.115): icmp_seq=2 ttl=128 时间=16.8 毫秒
64 字节,来自 106.15.38.115 (106.15.38.115): icmp_seq=3 ttl=128 时间=17.1 毫秒
64 字节,来自 106.15.38.115 (106.15.38.115): icmp_seq=4 ttl=128 时间=16.9 毫秒
64 字节,来自 106.15.38.115: icmp_seq=5 ttl=128 时间=15.7 毫秒
--- www.clockwingsoar.cyou ping 统计 ---
已发送 5 个包, 已接收 5 个包, 0% packet loss, time 4093ms
rtt min/avg/max/mdev = 15.740/16.974/18.290/0.813 ms
工作原理: 当用户输入一个不包含点(.)的主机名时,DNS 解析器会:
- 先尝试直接解析该主机名
- 如果失败,会依次尝试在主机名后添加
search列表中的每个域名后缀进行解析 - 直到找到匹配的 IP 地址或尝试完所有后缀
应用场景:
- 企业内部网络:方便员工访问内部服务器,如
ping web自动解析为web.company.com - 个人服务器:简化对自有域名下服务的访问
- 开发环境:快速访问测试服务器,提高开发效率
HTTP:从 1.1 到 3.0
- HTTP/1.1:文本协议,Keep-Alive 复用连接,但有队头阻塞 (Head-of-Line Blocking)。
- HTTP/2:二进制分帧,多路复用 (Multiplexing),头部压缩 (HPACK)。解决了应用层队头阻塞,但 TCP 层队头阻塞依然存在。
- HTTP/3 (QUIC):基于 UDP,彻底解决了 TCP 的队头阻塞,连接迁移更平滑。
4.5 链路层扩展:VLAN (Virtual LAN)
虚拟局域网 (VLAN) 是将物理网络划分为多个逻辑隔离的网段的技术。
通俗理解: 想象一个开放式大办公室(物理局域网),所有人说话大家都能听到(广播域)。 VLAN 就像是在这个大办公室里装上了隔音玻璃。
- 物理上:大家还坐在同一个房间里(连接在同一个交换机上)。
- 逻辑上:只有玻璃房内的人能互相交谈(同一 VLAN 内通信),听不到外面的嘈杂声(隔离广播)。
核心价值:
- 提升性能(隔绝噪音):限制广播报文的范围,避免”广播风暴”阻塞网络。
- 简化管理(灵活工位):员工换座位(物理位置变动),只需要在交换机上修改 VLAN 配置,不需要重新布线。
- 增强安全(部门隔离):财务部(VLAN 10)的数据不会被访客(VLAN 20)窃听。
[!NOTE] VLAN 只是逻辑隔离。不同 VLAN 之间要通信,必须通过路由器或三层交换机(相当于在隔音玻璃上开个门,并安排保安检查)。
4.6 进程间通信:SRE视角下的IPC机制
在分布式系统中,进程间通信(IPC)是服务协作的基础。从SRE角度看,理解IPC机制不仅有助于排查服务间通信问题,还能优化系统性能和可靠性。
4.6.1 IPC机制分类
| IPC机制 | 描述 | 典型应用场景 | SRE关注点 |
|---|---|---|---|
| 系统信号 (Signal) | 用于通知进程某个事件已发生 | 进程终止、异常处理 | 信号处理逻辑、core dump配置 |
| 管道 (Pipe) | 单向通信,适用于亲缘进程 | 命令行管道、日志传输 | 缓冲区大小、读写阻塞 |
| 套接字 (Socket) | 支持同一主机或跨主机通信 | 网络服务、微服务调用 | 连接管理、超时设置 |
| 文件锁 (File Lock) | 用于进程间共享文件同步 | 配置文件更新、日志写入 | 死锁风险、锁粒度 |
| 消息队列 (Message Queue) | 异步消息传递机制 | 任务队列、事件通知 | 队列长度、消息持久化 |
| 信号灯 (Semaphore) | 用于进程间同步与互斥 | 共享资源访问控制 | 信号量值、等待超时 |
4.6.2 SRE视角下的IPC用途
1. 服务可靠性保障
信号机制的应用:
- 优雅关闭:通过SIGTERM信号通知服务优雅关闭,确保正在处理的请求完成
- 异常监控:捕获SIGSEGV等崩溃信号,生成core dump用于事后分析
- 资源控制:通过SIGXCPU信号限制进程CPU使用,防止单个进程耗尽资源
实践案例:
# 配置core dump大小限制
ulimit -c unlimited
# 捕获崩溃信号并生成core dump
echo "core.%e.%p" > /proc/sys/kernel/core_pattern
2. 服务间协作优化
套接字通信:
- 本地套接字 (Unix Domain Socket):比TCP套接字更高效,适用于同一主机的服务间通信
- 连接池管理:通过IPC机制实现连接池共享,减少连接建立开销
- 超时控制:合理设置套接字超时,避免服务间调用级联失败
实践案例:
# 查看本地套接字连接
ss -x -l
# 检查套接字连接状态
netstat -an | grep -i listen
3. 资源争用管理
文件锁与信号灯:
- 配置文件保护:使用flock确保配置文件在更新时不被并发修改
- 共享资源控制:通过信号灯限制对数据库连接、磁盘IO等共享资源的访问
- 死锁检测:监控IPC资源使用,及时发现并解决死锁问题
实践案例:
# 使用flock实现原子操作
flock -x /var/run/myapp.lock -c "echo 'updating config' > /etc/myapp/config.conf"
4. 异步处理与流量削峰
消息队列:
- 流量缓冲:在流量峰值时,消息队列可缓冲请求,防止服务过载
- 解耦服务:通过消息队列实现服务间解耦,提高系统弹性
- 事件驱动架构:基于消息队列构建事件驱动系统,提高系统响应能力
实践案例:
# 查看消息队列使用情况
ipcs -q
# 清理未使用的消息队列
ipcs -q | grep -v key | awk '{print $2}' | xargs -r ipcrm -q
5. 系统监控与诊断
IPC状态监控:
- 连接数监控:监控TCP/UDP连接数,防止文件句柄耗尽
- 共享内存使用:监控共享内存段,防止内存泄漏
- 管道缓冲区:监控管道缓冲区使用情况,防止数据丢失
实践案例:
# 监控进程打开的文件描述符数
lsof -p <pid> | wc -l
# 查看系统IPC资源限制
ulimit -a
4.6.3 IPC相关问题排查
| 问题现象 | 可能原因 | 排查方法 |
|---|---|---|
| Too many open files | 文件描述符耗尽 | 检查ulimit设置、使用lsof查看进程打开的文件数 |
| 死锁 | 进程间循环等待资源 | 使用strace或gdb调试,查看进程等待状态 |
| 消息丢失 | 消息队列溢出 | 调整消息队列大小,增加消费者数量 |
| 连接重置 | 套接字超时或异常关闭 | 检查系统日志、使用tcpdump抓包分析 |
| 信号处理不当 | 信号未捕获或处理逻辑错误 | 检查信号处理函数,使用strace跟踪信号处理 |
4.6.4 SRE最佳实践
- 合理选择IPC机制:根据业务场景选择合适的IPC机制,如本地通信优先使用Unix套接字
- 设置合理的资源限制:根据服务需求调整文件描述符、消息队列长度等限制
- 实现优雅关闭:所有服务必须支持SIGTERM信号,确保优雅关闭
- 监控IPC资源:将IPC资源使用情况纳入监控系统,设置告警阈值
- 定期清理IPC资源:避免僵尸进程和未释放的IPC资源占用系统资源
- 测试异常场景:模拟信号中断、资源耗尽等场景,确保服务能正确处理
4.7 网络故障排查实战:Wireshark看不到虚拟机间流量
问题现象
在使用Wireshark监听VMnet8网卡时,只能看到10.0.0.12到10.0.0.1的流量,而看不到10.0.0.12到10.0.0.13的TCP流量,尽管执行curl 10.0.0.13能成功获取响应。
排查步骤
1. 验证网络连通性
# 在Rocky主机(10.0.0.12)上ping Ubuntu主机(10.0.0.13)
ping 10.0.0.13
PING 10.0.0.13 (10.0.0.13) 56(84) 比特的数据。
64 比特,来自 10.0.0.13: icmp_seq=1 ttl=64 时间=0.385 毫秒
64 比特,来自 10.0.0.13: icmp_seq=2 ttl=64 时间=0.382 毫秒
# 连通性正常
# 追踪路由,验证直接通信
0 ✓ 08:56:16 root@rocky9.6-12,10.0.0.12:~ # traceroute 10.0.0.13
traceroute to 10.0.0.13 (10.0.0.13), 30 hops max, 60 byte packets
1 10.0.0.13 (10.0.0.13) 0.379 ms 0.335 ms 0.313 ms
0 ✓ 08:56:23 root@rocky9.6-12,10.0.0.12:~ #
# 直接到达,只经过1跳,验证虚拟机间直接通信
2. 检查Nginx服务状态
# 在Ubuntu主机(10.0.0.13)上检查Nginx配置
cat /etc/nginx/sites-available/default
# 确认监听80端口
listen 80 default_server;
listen [::]:80 default_server;
# 检查Nginx是否正在监听80端口
ss -lntup | grep 80
tcp LISTEN 0 511 0.0.0.0:80 0.0.0.0:*
tcp LISTEN 0 511 [::]:80 [::]:*
# Nginx正常监听80端口
3. 分析问题原因
VMware NAT 模式的流量转发特性
在 VMware NAT 模式下,同一宿主机内的虚拟机之间通信时,VMware 虚拟交换机 (VMware Virtual Switch) 会直接转发流量,不经过宿主机的物理网卡。这是为了提高性能而设计的优化。
Wireshark 捕获的限制
Wireshark 运行在宿主机上,只能捕获经过宿主机物理网卡的流量。由于虚拟机间的流量被虚拟交换机直接转发,所以 Wireshark 看不到这些流量。
网关转发的例外情况
如果虚拟机访问外网(如 curl www.baidu.com),流量会经过网关 10.0.0.2,然后通过宿主机的物理网卡发送出去。此时 Wireshark 可以捕获到这些流量。
Wireshark 与 tcpdump 捕获差异的详细解释
为什么 Wireshark 只有 10.0.0.1 宿主机到 10.0.0.13 的 TCP 流量,而 tcpdump 能捕捉到来自 10.0.0.12 curl 命令的流量?
这是因为两者运行的位置和捕获范围不同:
| 工具 | 运行位置 | 捕获范围 | 结果差异 |
|---|---|---|---|
| Wireshark | 宿主机 | 仅经过宿主机物理网卡的流量 | 只能看到宿主机(10.0.0.1)与虚拟机(10.0.0.13)的通信,看不到虚拟机间直接通信 |
| tcpdump | 虚拟机内部 | 虚拟机网卡上的所有流量 | 可以看到虚拟机(10.0.0.12)与虚拟机(10.0.0.13)的直接通信 |
具体原因分析:
- 流量路径差异:
- 当 10.0.0.12 (Rocky) 访问 10.0.0.13 (Ubuntu) 时,流量直接通过 VMware 虚拟交换机转发,不经过宿主机网卡
- 当 10.0.0.1 (宿主机) 访问 10.0.0.13 (Ubuntu) 时,流量需要经过宿主机网卡,所以 Wireshark 能捕获到
- 捕获点不同:
- Wireshark 捕获的是宿主机物理网卡的流量,位于虚拟交换机外部
- tcpdump 捕获的是虚拟机内部网卡的流量,位于虚拟交换机内部
- VMware 虚拟网络架构:
+----------------+ +----------------+ +----------------+ | 宿主机(10.0.0.1)| | VMware 虚拟交换机 | | 虚拟机(10.0.0.13) | | | | | | | | Wireshark |<-----| |<-----| | | (捕获物理网卡) | | | | tcpdump | +----------------+ | | | (捕获虚拟网卡) | | | +----------------+ | | +----------------+ | | | 虚拟机(10.0.0.12) | | |<-----| | +----------------+ +----------------+
4. 解决方案
- 开启Wireshark混杂模式(推荐,最简单的解决方案):
- 打开Wireshark,选择要捕获的虚拟网卡(如VMnet8)
- 点击”选项”按钮,在捕获设置中勾选”混杂模式”选项
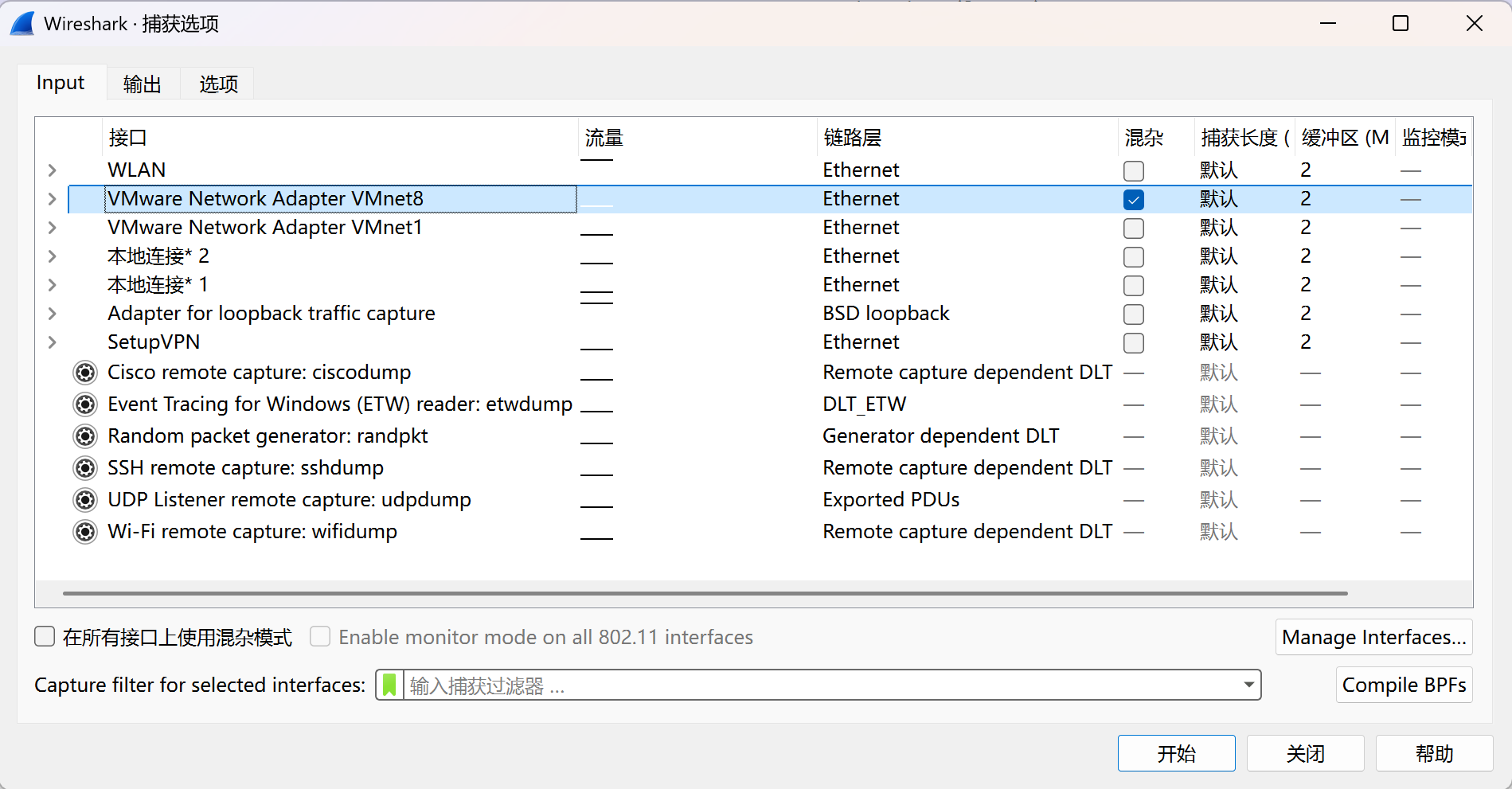
- 点击”开始捕获”,此时Wireshark可以捕获经过该虚拟网卡的所有流量,包括虚拟机间的直接通信
- 原理:默认情况下,网卡只接收目的地址为自己MAC地址的数据包,混杂模式下网卡会接收所有经过该网卡的数据包,无论目的地址是什么
- 使用虚拟机内部的网络工具(如
tcpdump)捕获流量:tcpdump -i eth0 tcp port 80 - 将VMware网络模式改为桥接模式,使虚拟机直接连接到物理网络
- 在VMware网络编辑器中调整NAT设置,让流量经过宿主机网卡以便捕获
4.7.1 VMware网络编辑器具体操作步骤
1. 打开VMware网络编辑器
- 在VMware Workstation主界面,点击顶部菜单
编辑>虚拟网络编辑器 - 或在Windows右下角找到VMware网络图标,右键选择
虚拟网络编辑器
2. 获取管理员权限
- 点击窗口右下角的
更改设置按钮,输入管理员密码获取权限
3. 选择NAT网络
- 在左侧列表中选择
VMnet8(NAT模式对应的虚拟网络) - 确保
已连接选项被勾选
4. 调整NAT设置
- 点击下方的
NAT设置按钮,打开NAT设置窗口 - 查看网关IP(通常为
10.0.0.2),确认与虚拟机配置一致
5. 虚拟机间流量捕获的特殊说明
为什么勾选了虚拟适配器仍无法捕获虚拟机间流量?
即使勾选了 将主机虚拟适配器连接到此网络 选项,您仍可能无法捕获到 10.0.0.12 和 10.0.0.13 之间的直接流量,这是由VMware NAT模式的内部转发机制决定的:
- 虚拟交换机内部转发:在NAT模式下,同一虚拟网络(VMnet8)内的虚拟机之间通信时,流量直接通过VMware内置的虚拟交换机转发,不经过宿主机的物理网卡或虚拟适配器
- 流量路径差异:
- 虚拟机到外部网络:
虚拟机 → 虚拟交换机 → NAT设备 → 宿主机网卡 → 外部网络 - 虚拟机到虚拟机:
虚拟机 → 虚拟交换机 → 另一虚拟机(完全在VMware虚拟网络栈内完成)
- 虚拟机到外部网络:
- Wireshark捕获限制:Wireshark只能捕获经过宿主机网卡或虚拟适配器的流量,无法直接访问VMware虚拟交换机内部的流量
针对虚拟机间流量的有效捕获方案
以下是专门针对虚拟机间流量捕获的解决方案:
方案1:使用VMware自带的Network Analyzer(推荐)
- VMware Workstation Pro 15+ 内置了
Network Analyzer功能,可以直接捕获虚拟机间的流量 - 操作路径:
虚拟机>捕获网络流量>开始 - 选择要监控的虚拟机和网络接口
- 捕获的流量会保存为
.pcap文件,可直接用Wireshark打开
方案2:修改虚拟机网络模式为”仅主机模式”
- 在虚拟机设置中,将网络适配器改为
仅主机模式(VMnet1) - 在虚拟网络编辑器中,确保VMnet1的
将主机虚拟适配器连接到此网络被勾选 - 这样同一VMnet1网络内的虚拟机通信流量会经过宿主机的VMnet1虚拟适配器
- 使用Wireshark监听VMnet1适配器即可捕获所有虚拟机间流量
方案3:在虚拟机内直接使用tcpdump
- 在Linux虚拟机中安装tcpdump:
sudo yum install tcpdump或sudo apt install tcpdump - 在
10.0.0.12或10.0.0.13虚拟机内执行:sudo tcpdump -i eth0 host 10.0.0.13 and port 3181 - 这样可以直接在虚拟机内部捕获进出的所有流量,不受VMware虚拟网络架构限制
方案4:使用桥接模式
- 将虚拟机网络适配器改为
桥接模式 - 虚拟机将直接连接到宿主机所在的物理网络
- 使用Wireshark监听宿主机物理网卡即可捕获所有虚拟机流量
6. 应用设置
- 点击
确定保存所有设置 - 重启VMware虚拟网络服务(可选,确保设置生效)
- 重启相关虚拟机以应用新的网络设置
4.7.2 验证解决方案
验证方法1:使用tcpdump在虚拟机内捕获
# 在10.0.0.12虚拟机上捕获到10.0.0.13的流量
sudo tcpdump -i eth0 host 10.0.0.13 and tcp port 3181
# 在10.0.0.13虚拟机上捕获到10.0.0.12的流量
sudo tcpdump -i eth0 host 10.0.0.12 and tcp port 3181
验证方法2:使用VMware Network Analyzer
- 启动Network Analyzer后,发起虚拟机间通信
- 检查捕获的pcap文件,确认包含虚拟机间的TCP流量
- 分析流量中的三次握手和数据传输过程
4.7.3 常见问题与解决方案
问题1:为什么Wireshark在宿主机上无法捕获虚拟机间流量?
- 原因:NAT模式下虚拟机间流量直接通过VMware虚拟交换机转发,默认情况下Wireshark只捕获目的地址为自己的数据包
- 解决方案:
- 最简单方法:在Wireshark捕获设置中开启”混杂模式”
- 替代方法:使用VMware Network Analyzer或在虚拟机内使用tcpdump
问题2:为什么没捕获到ping或traceroute流量?
- 协议不匹配:默认捕获命令可能只针对TCP协议,而
ping使用ICMP,traceroute默认使用UDP - 过滤器限制:需要调整捕获过滤器以包含相应协议
捕获不同协议流量的正确命令:
# 捕获ICMP流量(包括ping)
sudo tcpdump -i eth0 icmp
# 捕获UDP流量(包括默认traceroute)
sudo tcpdump -i eth0 udp
# 捕获特定端口的TCP流量
sudo tcpdump -i eth0 tcp port 3181
# 捕获所有流量
sudo tcpdump -i eth0
问题3:如何确认VMware虚拟网络设置正确?
- 检查虚拟机的网络配置:
ip addr和ip route - 验证虚拟机间连通性:
ping 10.0.0.13 - 检查虚拟网络编辑器中的设置,确保对应网络已连接
- 重启VMware虚拟网络服务:在Windows服务中重启
VMware NAT Service和VMware DHCP Service
用户实际捕获结果分析:
# 用户在10.0.0.13上执行的命令
sudo tcpdump -i eth0 tcp port 80
# 捕获到10.0.0.12访问docker.nju.edu.cn的HTTP流量,这是因为:
# 1. 该流量使用TCP协议且端口为80
# 2. 匹配了当前过滤器条件
# 3. ping和traceroute使用其他协议,因此未被捕获
SRE 经验总结
- 混杂模式的重要性:在捕获虚拟网络流量时,务必开启Wireshark的混杂模式,这是最简单有效的解决方案
- 工具局限性:不同工具的捕获范围不同,理解工具的工作原理和捕获范围至关重要
- 网络模式理解:深入理解VMware各种网络模式的流量路径
- 多工具协作:结合
ping、ss、tcpdump和Wireshark等工具进行全面排查 - 配置验证:确认服务监听配置和网络连通性是排查的基础
[!TIP] netcat 是 SRE 工具箱中的瑞士军刀,掌握它可以快速解决很多网络相关问题。
4.8 SRE 排查工具箱 (Troubleshooting Toolkit)
工欲善其事,必先利其器。
4.8.1 系统信息与网络基础:hostnamectl 和 ping
hostnamectl - 查看系统主机名和网络状态
hostnamectl 命令用于显示和设置系统的主机名及相关信息,是 SRE 排查网络问题时的基础工具之一。
示例输出:
root@ubuntu24,10.0.0.113:~ # hostnamectl status
Static hostname: ubuntu24
Icon name: computer-vm
Chassis: vm 🖴
Machine ID: 5dc5cd989883432e9d25d4ab5e50161d
Boot ID: 5ed21e58b1954532a5eddea4640ece58
Virtualization: vmware
Operating System: Ubuntu 24.04.3 LTS
Kernel: Linux 6.14.0-36-generic
Architecture: x86-64
Hardware Vendor: VMware, Inc.
Hardware Model: VMware Virtual Platform
Firmware Version: 6.00
Firmware Date: Thu 2020-11-12
Firmware Age: 5y 2w 1d
SRE 关注点:
- 静态主机名:确认系统主机名是否与配置一致,避免因主机名解析问题导致的服务异常
- IP 地址:命令提示符中显示的 IP 地址(10.0.0.113)可快速确认当前系统的网络身份
- 虚拟化信息:确认系统运行环境(VMware 虚拟机),有助于排查虚拟化相关的网络问题
- 操作系统版本:Ubuntu 24.04.3 LTS,不同版本的网络配置工具和行为可能有所差异
- 内核版本:Linux 6.14.0-36-generic,内核版本影响网络协议栈的行为和性能
ping - 测试网络连通性
ping 命令是最基础的网络连通性测试工具,使用 ICMP 协议发送回显请求,用于验证目标主机是否可达。
示例输出:
root@ubuntu24,10.0.0.113:~ # ping 10.0.0.115
PING 10.0.0.115 (10.0.0.115) 56(84) bytes of data.
64 bytes from 10.0.0.115: icmp_seq=1 ttl=64 time=0.726 ms
64 bytes from 10.0.0.115: icmp_seq=2 ttl=64 time=0.665 ms
64 bytes from 10.0.0.115: icmp_seq=3 ttl=64 time=1.04 ms
64 bytes from 10.0.0.115: icmp_seq=4 ttl=64 time=0.928 ms
^C
--- 10.0.0.115 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3073ms
rtt min/avg/max/mdev = 0.665/0.840/1.041/0.151 ms
SRE 关注点:
- 丢包率:0% 表示网络连通性良好,高丢包率可能指示网络拥塞或链路问题
- 延迟:avg 0.840 ms 表示低延迟,适合实时应用;高延迟可能影响服务响应时间
- TTL 值:64 是 Linux 系统默认值,通过 TTL 变化可判断数据包经过的路由跳数
- 抖动:mdev 0.151 ms 表示延迟抖动小,网络稳定性好
4.8.2 路由表分析:route 和 route -n
路由表是网络通信的核心,route 命令用于显示和管理 IP 路由表,是 SRE 排查网络可达性问题的关键工具。
查看路由表
使用 route 查看(解析主机名):
root@ubuntu24,10.0.0.113:~ # route
内核 IP 路由表
目标 网关 子网掩码 标志 跃点 引用 使用 接口
default _gateway 0.0.0.0 UG 100 0 0 eth0
10.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
10.0.0.0 0.0.0.0 255.255.255.0 U 101 0 0 eth2
10.0.0.0 0.0.0.0 255.255.255.0 U 102 0 0 eth1
使用 route -n 查看(不解析主机名,更快):
root@ubuntu24,10.0.0.113:~ # route -n
内核 IP 路由表
目标 网关 子网掩码 标志 跃点 引用 使用 接口
0.0.0.0 10.0.0.2 0.0.0.0 UG 100 0 0 eth0
10.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
10.0.0.0 0.0.0.0 255.255.255.0 U 101 0 0 eth2
10.0.0.0 0.0.0.0 255.255.255.0 U 102 0 0 eth1
添加路由的多种方法
1. 添加主机路由
root@rocky9.6-12,10.0.0.12:~ # route add -host 192.168.1.3 gw 10.0.0.12 dev ens160
2. 添加网络路由(使用 netmask 参数)
root@rocky9.6-12,10.0.0.12:~ # route add -net 192.168.1.0 netmask 255.255.255.0 gw 10.0.0.12 dev ens160
3. 添加网络路由(使用 CIDR 表示法)
root@rocky9.6-12,10.0.0.12:~ # route add -net 192.168.2.0/24 gw 10.0.0.12 dev ens160
4. 添加直连路由(带 metric)
root@rocky9.6-12,10.0.0.12:~ # route add -net 192.168.8.0/24 dev ens160 metric 200
最终路由表(route -n):
root@rocky9.6-12,10.0.0.12:~ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.2 0.0.0.0 UG 100 0 0 ens160
10.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 ens160
192.168.1.0 10.0.0.12 255.255.255.0 UG 0 0 0 ens160
192.168.1.3 10.0.0.12 255.255.255.255 UGH 0 0 0 ens160
192.168.2.0 10.0.0.12 255.255.255.0 UG 0 0 0 ens160
192.168.8.0 0.0.0.0 255.255.255.0 U 200 0 0 ens160
SRE 关注点:
- 默认路由:
0.0.0.0目标指向网关10.0.0.2,通过eth0接口,跃点 100 - 网络设备定义:
- 这里的”网络设备”是广义概念,包括路由器、服务器电脑、个人电脑等所有具备网络功能的设备
- 这些设备都有自己的路由表,都需要根据路由表决定IP数据包的转发路径
- 无论是企业级路由器还是普通办公电脑,路由表的工作原理基本相同
- 直连路由:
- 定义:当网络设备的接口配置了 IP 地址和子网掩码后,设备会自动生成的指向该接口所在网段的路由
- 特点:网关为
0.0.0.0(无网关),数据包可直接通过本地接口发送到目标网段 - 示例:三个
10.0.0.0/24网段的直连路由,分别对应eth0、eth2、eth1接口 - eth0 与网关的区别:
eth0是本地网络接口,是数据包发送的物理或虚拟出口- 网关是远程设备的 IP 地址,用于转发数据包到非直连网段
- 在直连路由中,
eth0不等于网关,而是直接发送数据包的接口,无需通过网关转发 - 数据包可以直接通过
eth0发送到同一网段的设备,不需要中间转发设备
- 跃点值(Metric):
- 定义:路由的度量值,用于表示路由的优先级
- 优先级关系:跃点值越小,路由优先级越高
- 示例:eth0 跃点 100,eth2 跃点 101,eth1 跃点 102,因此 eth0 优先级最高
- 作用:当存在多条到达同一目标网段的路由时,设备会选择跃点值最小的路由
- 多接口同网段:同一
10.0.0.0/24网段有三个接口,可能用于负载均衡或冗余 - 网关 IP:
route -n显示的是实际 IP 地址10.0.0.2,而route显示的是解析后的主机名_gateway - 路由类型标志:
U:路由已启用G:路由指向网关H:主机路由(目标是单台主机)
SRE 实战应用:
- 主机路由(
route add -host)- 用途:针对单个 IP 地址的精确路由控制
- SRE 场景:
- 指向特定服务节点的专用路由
- 测试环境中临时指向特定服务器
- 为重要应用服务器配置直达路由,减少网络延迟
- 优势:精确控制单台主机的流量走向,适合对延迟敏感的应用
- 网络路由(使用 netmask 参数)
- 用途:为整个网段添加路由,传统的完整写法
- SRE 场景:
- 连接到传统网络设备或旧版系统
- 需要明确指定子网掩码的场景
- 与旧版脚本或自动化工具兼容
- 优势:兼容性好,语法清晰,适合需要明确子网掩码的场景
- 网络路由(使用 CIDR 表示法)
- 用途:为整个网段添加路由,现代简洁写法
- SRE 场景:
- 现代网络环境中的路由配置
- 云环境或容器网络配置
- 自动化脚本和配置管理工具(如 Ansible、Terraform)
- 优势:语法简洁,不易出错,符合现代网络配置习惯
- 直连路由(带 metric)
- 命令示例:
route add -net 192.168.8.0/24 dev eth0 metric 200 - 详细作用解析:
route add:添加路由的命令-net 192.168.8.0/24:指定目标网段为192.168.8.0/24(CIDR 表示法,24位掩码)dev eth0:指定数据包通过eth0接口发送到该网段metric 200:设置该路由的跃点值为 200
- 实际效果:
- 当系统需要发送数据包到
192.168.8.0/24网段时,会将数据包通过eth0接口直接发送 - 由于设置了 metric 200,如果系统中存在其他到
192.168.8.0/24网段的路由(如 metric 100),则会优先选择 metric 更小的路由 - 只有当高优先级路由不可用时,才会使用这条 metric 200 的路由
- 当系统需要发送数据包到
- eth0 在直连路由中的角色:
eth0是数据包的出口接口,而非网关- 直连路由中没有网关(网关为
0.0.0.0),因为目标网段直接连接在eth0上 - 数据包从
eth0发送后,直接到达目标网段,不需要经过任何中间网关设备 - 网关的作用是转发到非直连网段,而直连网段不需要转发
- 网段判断方法:
- 如何判断两个 IP 是否在同一网段:通过 IP 地址和子网掩码的与运算计算网络地址
- 计算示例:
- 当前机器 IP:
10.0.0.12,假设子网掩码为255.255.255.0(24位) - 网络地址计算:
10.0.0.12 & 255.255.255.0 = 10.0.0.0→ 网段为10.0.0.0/24 - 目标网段
192.168.8.0/24的网络地址是192.168.8.0
- 当前机器 IP:
- 结论:
192.168.8.0/24和10.0.0.12(属于10.0.0.0/24网段)不在同一网段
- 为什么配置为直连路由:
- 虽然
192.168.8.0/24和当前机器的10.0.0.12不在同一网段,但通过dev eth0配置为直连路由,可能有以下原因:- VLAN 配置:
eth0接口可能配置了 VLAN,允许访问多个网段 - 虚拟接口:
eth0可能有子接口(如eth0.100)或绑定了多个 IP 地址 - 测试环境:临时添加路由用于测试,不遵循常规网络设计
- 特殊网络拓扑:如
eth0连接到支持多网段的交换机或路由器 - 虚拟机网络:在 VMware 等虚拟机环境中,虚拟网络适配器可能同时连接到多个虚拟网络
- VLAN 配置:
- 虽然
- VMware 网络模式与连通性案例:
- 案例描述:
- 虚拟机 IP:
10.0.0.13/24(NAT 模式,VMnet8) - VMware 配置:仅主机模式网络(VMnet1)子网为
192.168.8.0/24 - 现象:
ping -I eth0 192.168.8.1成功,但ip addr看不到192.168.8.0/24配置
- 虚拟机 IP:
- 原因分析:
- VMware 虚拟网络架构:VMware 为每个虚拟网络模式创建独立的虚拟交换机
- NAT 模式特性:NAT 模式下,VMware 会自动配置路由,允许虚拟机访问主机的其他虚拟网络
- 隐式路由:VMware 主机作为网关,在内部维护了从
10.0.0.0/24到192.168.8.0/24的路由 - 为什么
ip addr看不到:因为192.168.8.0/24不是配置在虚拟机的eth0接口上,而是通过 VMware 的 NAT 引擎实现的连通性
- 验证方法:
- 查看 VMware 主机的路由表:在 Windows 主机上执行
route print或 Linux 主机上执行ip route - 检查 VMware NAT 设置:虚拟网络编辑器中的 NAT 配置
- 测试不同接口的连通性:
ping -I eth0 192.168.8.1vsping 192.168.8.1(不指定接口)
- 查看 VMware 主机的路由表:在 Windows 主机上执行
- 案例描述:
- 实际应用场景:
- 多网络环境测试:一台虚拟机可以同时访问多个虚拟网络,用于测试跨网络通信
- 开发与测试隔离:NAT 模式用于访问外部网络,仅主机模式用于内部测试网络
- 安全隔离:不同虚拟网络间的通信由 VMware 控制,提高安全性
- 如何验证:
- 查看当前机器的 IP 配置:
ip addr show eth0或ifconfig eth0 - 检查
eth0是否配置了多个 IP 或 VLAN:ip addr - 测试路由连通性:
ping -I eth0 192.168.8.1 - 查看完整路由表:
ip route show或route -n
- 查看当前机器的 IP 配置:
- 路由删除操作案例(Rocky Linux 9.6):
- 初始路由表:
Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 10.0.0.2 0.0.0.0 UG 100 0 0 ens160 10.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 ens160 192.168.1.0 10.0.0.12 255.255.255.0 UG 0 0 0 ens160 192.168.1.3 10.0.0.12 255.255.255.255 UGH 0 0 0 ens160 192.168.2.0 10.0.0.12 255.255.255.0 UG 0 0 0 ens160 192.168.8.0 0.0.0.0 255.255.255.0 U 200 0 0 ens160 - 删除主机路由:
route del -host 192.168.1.3 # 成功删除主机路由 - 删除网络路由(错误方式):
route del -net 192.168.1.0 # 失败,提示"无效的参数" - 删除网络路由(正确方式1):
route del -net 192.168.1.0 netmask 255.255.255.0 # 成功删除 - 删除网络路由(正确方式2 - 使用CIDR):
route del -net 192.168.2.0/24 # 成功删除,使用CIDR表示法 - 删除直连路由:
route del -net 192.168.8.0/24 # 成功删除直连路由 - 最终路由表:
Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 10.0.0.2 0.0.0.0 UG 100 0 0 ens160 10.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 ens160 - 操作说明:
- 删除路由时,需要指定正确的路由类型(-host或-net)
- 使用
route del -net时,需要指定完整的网络地址和子网掩码,或使用CIDR表示法 - 主机路由需要使用
-host选项 - 可以删除各种类型的路由,包括直连路由、静态路由和默认路由
- 初始路由表:
- SRE 场景:
- 多网卡负载均衡:在有多个网卡连接到同一或不同网络时,通过设置不同 metric 值分配流量
- 冗余备份:为重要网段设置主备路由,主路由 metric 小,备路由 metric 大,主路由故障时自动切换到备路由
- 测试环境:临时添加测试网段路由,不影响现有生产路由(因为 metric 较高,不会被优先选择)
- 网络迁移:在网络架构调整过程中,逐步过渡流量,通过调整 metric 值控制流量切换
- 优势:
- 通过 metric 值精确控制路由优先级
- 灵活调整流量走向,适应不同网络场景
- 支持冗余设计,提高网络可靠性
- metric 与优先级:
- 示例中
192.168.8.0/24网段的直连路由 metric 为 200 - 若存在另一条到
192.168.8.0/24的路由,metric 为 100,则会优先选择 metric 100 的路由 - metric 值越大,优先级越低;metric 值越小,优先级越高
- 示例中
- 命令示例:
路由排查实战技巧:
- 排查”无法访问外部网络”问题时,首先检查默认路由是否存在
- 排查”特定网段无法访问”问题时,检查对应网段的路由条目
- 多接口同网段场景下,通过跃点值控制流量走向
- 使用
route -n避免 DNS 解析延迟,适合在 DNS 服务异常时使用 - 主机路由优先级高于网络路由,适合精确流量控制
- 直连路由无需网关,直接通过本地接口转发,效率更高
- 对于
route add -net 192.168.8.0/24 dev eth0 metric 200类型的路由配置,SRE 需关注:- 确认
eth0接口是否正常启用且配置了合适的 IP 地址 - 验证 metric 值设置是否符合预期的优先级需求
- 测试该路由是否按预期工作:
ping -I eth0 192.168.8.1 - 在生产环境中,应使用持久化路由配置(如
/etc/sysconfig/network-scripts/route-eth0或 NetworkManager),避免重启后路由丢失
- 确认
4.8.3 网络接口状态:ifconfig -s
ifconfig -s 命令用于显示网络接口的简要统计信息,是 SRE 监控网络接口健康状态的常用工具。
示例输出:
root@ubuntu24,10.0.0.113:~ # ifconfig -s
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 448484 0 0 0 90527 0 34 0 BMRU
eth1 1500 30 0 0 0 143 0 0 0 BMRU
eth2 1500 881 0 0 0 230 0 0 0 BMRU
lo 65536 902 0 0 0 902 0 0 0 LRU
v-peer1 1500 143 0 0 0 30 0 0 0 BMRU
SRE 关注点:
- 接口状态标志:
B:广播功能已启用M:混杂模式已启用R:接口已启用U:接口处于活动状态L:回环接口
- 错误统计:
RX-ERR:接收错误包数量,非零值表示物理链路或驱动问题TX-ERR:发送错误包数量,非零值表示网络拥塞或硬件故障RX-DRP/TX-DRP:丢包数量,eth0的TX-DRP为 34,可能指示发送队列已满
- 流量统计:
RX-OK:成功接收的数据包数量,eth0接收了 448,484 个包,是主要流量接口TX-OK:成功发送的数据包数量,eth0发送了 90,527 个包
- MTU 值:
eth0/eth1/eth2的 MTU 为 1500(标准以太网 MTU),lo为 65536(回环接口) - 虚拟接口:
v-peer1是虚拟接口,可能用于容器或虚拟机通信
SRE 实战应用:
- 监控
RX-ERR/TX-ERR识别物理链路故障 - 分析
RX-DRP/TX-DRP排查网络拥塞问题 - 对比不同接口的流量统计,识别主要流量路径
- 检查接口状态标志,确认接口是否正常启用
4.8.4 查看连接状态:ss (Socket Statistics)
比 netstat 更快更强。
# 查看所有 TCP 连接并显示进程名
ss -ntlp
# 统计各种状态的连接数(排查 TIME_WAIT/CLOSE_WAIT 神器)
ss -ant | awk '{print $1}' | sort | uniq -c | sort -rn
# 输出示例:
# 800 ESTABLISHED
# 50 TIME_WAIT
# 10 LISTEN
4.8.2 抓包分析:tcpdump
# 抓取 eth0 网卡,端口 80,排除 SSH,保存到文件
tcpdump -i eth0 port 80 and not port 22 -w capture.pcap
# 抓取特定 IP 的包,显示详细信息
tcpdump -i any host 192.168.1.100 -nn -vv
4.8.3 DNS 诊断:dig
# 查询 A 记录,显示查询时间
dig www.google.com
# 指定 DNS 服务器查询
dig @8.8.8.8 www.google.com
# 追踪解析过程
dig +trace www.google.com
4.8.4 综合连通性:curl
# 查看详细的连接耗时(DNS、TCP、SSL、TTFB)
curl -w "\nDNS: %{time_namelookup}s\nTCP: %{time_connect}s\nSSL: %{time_appconnect}s\nTTFB: %{time_starttransfer}s\nTotal: %{time_total}s\n" -so /dev/null https://www.baidu.com
4.8.5 文件描述符网络通信:/dev/tcp 伪设备
/dev/tcp 是 Bash 提供的一种特殊伪设备,允许通过文件描述符直接进行 TCP 网络通信。尽管 ls /dev/tcp 会显示”没有那个文件或目录”,但它是 Bash 内核中的一个虚拟设备,用于模拟网络套接字。
5.1 基本原理与使用示例
# 示例1:创建双向文件描述符连接到百度
root@rocky9:~# exec 8<>/dev/tcp/www.baidu.com/80
# 查看文件描述符状态
root@rocky9:~# ll /proc/$$/fd
lrwx------ 1 root root 64 11月 26 15:08 8 -> 'socket:[137398]' # 已创建套接字
# 发送 HTTP 请求
root@rocky9:~# echo -e "GET / HTTP/1.1\nHost: www.baidu.com\n\n" >&8
# 读取响应
root@rocky9:~# cat <&8
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: no-cache
Connection: keep-alive
Content-Length: 29506
...
# 示例2:仅测试 TCP 连通性(不发送数据)
root@rocky9:~# < /dev/tcp/127.0.0.1/80 # 成功,无输出
root@rocky9:~# < /dev/tcp/127.0.0.1/8088 # 失败,返回连接拒绝
-bash: connect: 拒绝连接
-bash: /dev/tcp/127.0.0.1/8088: 拒绝连接
5.2 SRE 视角的使用场景
1. 轻量级连通性测试
- 优势:无需依赖
curl、telnet等外部工具,纯 Bash 内置实现 - 适用场景:容器镜像精简(仅保留 Bash)、嵌入式系统、初始化脚本
- 示例:启动脚本中检查服务端口是否就绪
# 等待服务启动完成 while ! < /dev/tcp/localhost/8080 2>/dev/null; do sleep 1 done
2. 批量端口扫描
- 优势:单进程、低资源消耗,适合快速扫描大量端口
- 适用场景:服务发现、安全审计、配置验证
- 示例:扫描 1-1000 端口,输出开放的端口
for port in {1..1000}; do < /dev/tcp/192.168.1.100/$port 2>/dev/null && echo "Port $port is open" done
3. 长连接保持与心跳检测
- 优势:通过文件描述符可以轻松管理长连接
- 适用场景:监控系统、负载均衡器健康检查、服务间心跳
- 示例:定期发送心跳包保持连接
exec 9<>/dev/tcp/monitor-server/9000 while true; do echo "PING $(date)" >&9 read -t 1 response <&9 [ $? -eq 0 ] && echo "Heartbeat received: $response" || echo "No response" sleep 60 done
4. 网络延迟基准测试
- 优势:排除应用层协议开销,仅测试 TCP 连接建立时间
- 适用场景:网络质量评估、跨 AZ/Region 延迟测试、CDN 节点选择
- 示例:测试连接建立延迟
time bash -c "< /dev/tcp/baidu.com/80" # 输出:0.02s user 0.01s system 0% cpu 0.150 total
5. 生产环境应急排查
- 优势:在系统资源耗尽(如内存不足、磁盘满)时,基础工具可能无法运行,但 Bash 内置功能仍可用
- 适用场景:系统崩溃前诊断、工具依赖损坏、容器资源受限
- 示例:在高负载下测试核心服务连通性
# 当 top/ps 等工具无法运行时 if < /dev/tcp/db-server/3306 2>/dev/null; then echo "Database connectivity: OK" else echo "Database connectivity: FAILED" fi
5.3 生产实践注意事项
- 仅支持 Bash:
/dev/tcp是 Bash 特性,不支持其他 shell(如 sh、dash) - 无超时机制:默认情况下,连接尝试会一直阻塞,建议使用
timeout命令包装timeout 5 bash -c "< /dev/tcp/unreachable-host/80" || echo "Connection timed out" - 资源泄漏风险:使用
exec创建的文件描述符需手动关闭,否则会持续占用资源exec 8<>/dev/tcp/example.com/80 # 使用完毕后关闭 exec 8<&- exec 8>&- - 权限限制:在容器或受限环境中,可能被 SELinux 或 AppArmor 限制使用
4.8.6 物理链路诊断:mii-tool 与 ethtool
当怀疑是物理层问题(如网线松动、协商速率不匹配)时,我们需要查看网卡的底层状态。
5.1 传统工具:mii-tool
在较老的系统或特定的物理网卡上,mii-tool 非常直观。
root@ubuntu24:~# mii-tool -v ens33
ens33: negotiated 1000baseT-FD flow-control, link ok
# 协商结果:1000Mbps 全双工 (FD),启用了流量控制。
# link ok:物理连接正常。
product info: Yukon 88E1011 rev 3
# 网卡型号信息
basic mode: autonegotiation enabled
# 开启了自动协商,网卡会尝试与对端交换信息以选择最佳模式。
basic status: autonegotiation complete, link ok
# 自动协商成功完成。
capabilities: 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
# 本端网卡支持的能力:1000/100/10 Mbps 的全双工/半双工。
advertising: 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
# 本端宣告的能力。
link partner: 1000baseT-HD 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
# 对端设备(交换机)支持的能力。
局限性: 在现代 Linux 发行版(如 Rocky Linux 9)或虚拟化环境(如 VMware/KVM)中,mii-tool 可能会失效,因为它依赖的旧接口可能不被支持。
[root@rocky9 ~]# mii-tool ens160
SIOCGMIIPHY on 'ens160' failed: Operation not supported
# 原因:网卡驱动不支持 MII 寄存器访问(常见于 vmxnet3 等虚拟网卡)。
5.2 现代标准:ethtool
ethtool 是目前 Linux 下配置和查询网卡参数的标准工具,功能比 mii-tool 更强大。
查看网卡物理状态:
[root@rocky9 ~]# ethtool ens160
Settings for ens160:
Supported ports: [ TP ]
# 介质类型:双绞线 (Twisted Pair)
Supported link modes: 1000baseT/Full
10000baseT/Full
# 支持的模式:千兆和万兆全双工
Supports auto-negotiation: No
# 不支持自动协商(虚拟网卡常见)
Speed: 10000Mb/s
# 当前速率:万兆
Duplex: Full
# 双工模式:全双工
Link detected: yes
# 物理链路正常
查看驱动与固件信息:
通过 ethtool -i 可以区分物理网卡和虚拟网卡,这对于排查性能问题(如是否需要开启 TSO/GSO Offload)很重要。
# Ubuntu (VMware e1000 模拟网卡)
root@ubuntu24:~# ethtool -i ens33
driver: e1000
version: 6.8.0-45-generic
bus-info: 0000:02:01.0
# Rocky Linux (VMware vmxnet3 半虚拟化网卡)
[root@rocky9 ~]# ethtool -i ens160
driver: vmxnet3
# vmxnet3 是 VMware 的高性能半虚拟化驱动
version: 1.7.0.0-k-NAPI
bus-info: 0000:03:00.0
SRE 关注点:
- Link Status:
Link detected: no意味着网线没插好或交换机端口关闭。 - Duplex/Speed: 确认协商速率是否符合预期(比如千兆变百兆),以及是否全双工。
4.8.7 网络接口配置与状态:ip addr
ip addr 是 iproute2 套件中最基础的命令,用于查看 IP 地址和接口状态。相比旧的 ifconfig,它能显示更多细节。
[root@rocky9 ~]# ip addr show ens160
2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b1:f4:54 brd ff:ff:ff:ff:ff:ff
altname enp3s0
inet 10.0.0.12/24 brd 10.0.0.255 scope global noprefixroute ens160
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:feb1:f454/64 scope link noprefixroute
valid_lft forever preferred_lft forever
详细解读:
- 接口状态与标志:
<BROADCAST,MULTICAST,UP,LOWER_UP>UP: 管理状态为开启(即管理员执行了ip link set up)。LOWER_UP: 物理层状态为开启(即网线已插好,物理链路正常)。- SRE 提示:如果只有
UP没有LOWER_UP,说明网线没插好或交换机端口没开。
- MTU & Qdisc:
mtu 1500 qdisc mqmtu 1500: 最大传输单元为 1500 字节(以太网标准)。如果两端 MTU 不一致(如一端开启巨型帧 9000),会导致大包丢弃。qdisc mq: 排队规则 (Queueing Discipline)。mq表示多队列,常见于多核 CPU 和高性能网卡。
- MAC 地址:
link/ether 00:0c:29:b1:f4:54- 定义:48位二进制地址,固化在网卡 ROM 中。
- 前 24 位 (OUI):组织唯一标识符 (Organizationally Unique Identifier),标识制造商 (如
00:0c:29代表 VMware)。 - 后 24 位 (DUI):设备唯一标识符 (Device Unique Identifier),由厂商分配。
- 前 24 位 (OUI):组织唯一标识符 (Organizationally Unique Identifier),标识制造商 (如
- 快速查看命令:
- Linux:
ip addr show ens160 | grep ether - Windows:
ipconfig /all
- Linux:
brd ff:ff:ff:ff:ff:ff: 广播地址,代表所有 MAC 地址。
- 定义:48位二进制地址,固化在网卡 ROM 中。
- IPv4 地址:
inet 10.0.0.12/24brd 10.0.0.255: 广播地址。scope global: 全局有效,可用于互联网通信。noprefixroute: 不自动添加路由(通常由 NetworkManager 管理)。
- IPv6 地址:
inet6 fe80::.../64scope link: 仅在本地链路有效(Link-Local),不可路由到互联网。valid_lft forever: 地址永久有效。
4.9 实战案例:openEuler 网卡重命名问题修复
在实际生产环境中,我们经常需要将系统默认的可预测接口名(如 ens160)修改为传统的 eth0 命名方式。但在 openEuler 系统中,简单修改配置文件可能会导致网卡无法启动。下面我们通过一个实际案例来详细分析和解决这个问题。
4.9.1 问题现象
用户在 openEuler 系统中将网卡重命名为 eth0,但重启后 eth0 接口无法启动。执行相关命令查看状态:
# 查看当前接口状态
ip a
# 实际接口名为 ens160
# 查看网络配置文件
cat /etc/sysconfig/network-scripts/ifcfg-eth0
# 配置文件已设置为 eth0
# 尝试启动网络连接
nmcli conn up eth0
# 错误信息:connection activation failed: No suitable device found for this connection
4.9.2 问题分析
从输出可以看出:
- 系统实际使用的接口名是
ens160(可预测接口名) - 网络配置文件已配置为
eth0 - NetworkManager 找不到与
eth0配置文件匹配的设备
4.9.3 根本原因
系统仍在使用可预测接口名称 ens160 而非 eth0,因为重命名配置未正确应用。这导致配置的接口名(eth0)与实际设备名(ens160)不匹配。
4.9.4 修复步骤
方法一:使用内核参数(推荐用于传统命名)
此方法完全禁用可预测接口名称,强制使用传统的 eth0、eth1 等命名方式。
# 向 GRUB 配置添加内核参数
grubby --update-kernel=ALL --args="net.ifnames=0 biosdevname=0"
# 验证更改
grubby --info=ALL | grep args
方法二:使用 systemd.link 文件(特定接口命名)
此方法允许基于 MAC 地址重命名特定接口。
# 首先查看接口的 MAC 地址
ip a show ens160 | grep ether
# 为 eth0 创建链接文件
cat > /etc/systemd/network/10-eth0.link << EOF
[Match]
MACAddress=xx:xx:xx:xx:xx:xx # 替换为实际 MAC 地址
[Link]
Name=eth0
EOF
方法三:使用 udev 规则(已弃用但仍有效)
# 创建或编辑 udev 规则文件
cat > /etc/udev/rules.d/70-persistent-net.rules << EOF
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="xx:xx:xx:xx:xx:xx", ATTR{type}=="1", KERNEL=="ens*", NAME="eth0"
EOF
更新网络配置(如有需要)
确保 /etc/sysconfig/network-scripts/ifcfg-eth0 文件设置正确:
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=eui64
NAME=eth0
UUID=8b147ea5-d76c-4868-9114-6d4a0296350f # 保留现有 UUID
DEVICE=eth0
ONBOOT=yes
IPADDR=18.8.8.8 # 你的 IP 地址
PREFIX=24
GATEWAY=18.8.8.2
DNS1=223.5.5.5
DNS2=223.6.6.6
重启系统
reboot
验证修复
# 检查接口是否已重命名为 eth0
ip a
# 检查 NetworkManager 连接
nmcli conn show
# 测试网络连通性
ping 8.8.8.8
4.9.5 扩展案例:手动创建虚拟网卡接口
问题现象:用户创建了 ifcfg-eth1 配置文件,但系统中只有 eth0 网卡,执行 nmcli conn up eth1 时出现错误:
错误:连接激活失败:No suitable device found for this connection (device eth0 not available because profile is not compatible with device (mismatching interface name)).
问题分析:
- 系统中不存在
eth1设备,所以 NetworkManager 无法启动eth1连接 - 错误信息提到
eth0是因为它是系统中唯一的网卡,NetworkManager 尝试匹配但失败
解决方案:使用 dummy 内核模块创建虚拟 eth1 接口
步骤1:加载 dummy 内核模块
# 临时加载 dummy 模块
modprobe dummy
# 设置开机自动加载
echo "dummy" > /etc/modules-load.d/dummy.conf
步骤2:创建虚拟 eth1 接口
# 使用 ip 命令创建 dummy 接口并命名为 eth1
ip link add eth1 type dummy
# 激活接口
ip link set eth1 up
步骤3:验证虚拟接口创建成功
# 查看接口状态
ip a show eth1
步骤4:启动 NetworkManager 连接
# 启动 eth1 连接
nmcli conn up eth1
# 查看连接状态
nmcli conn show
步骤5:设置开机自动创建虚拟接口
创建 systemd 服务确保开机自动创建 eth1 接口:
cat > /etc/systemd/system/create-eth1.service << EOF
[Unit]
Description=Create virtual eth1 interface
After=network.target
[Service]
Type=oneshot
ExecStart=/usr/sbin/ip link add eth1 type dummy
ExecStart=/usr/sbin/ip link set eth1 up
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
EOF
# 启用并启动服务
systemctl enable create-eth1.service
systemctl start create-eth1.service
步骤6:验证完整解决方案
# 查看所有接口
ip a
# 查看所有连接
nmcli conn show
# 测试 eth1 的网络连通性
ping -I eth1 10.0.0.2
4.9.6 故障排除提示
- 检查 MAC 地址:确保使用了正确的接口 MAC 地址
- GRUB 配置:验证内核参数是否正确添加
- 链接文件权限:确保
.link文件权限正确(644) - NetworkManager 状态:查看 NetworkManager 日志获取详细错误
journalctl -u NetworkManager -f - UUID 冲突:如果存在重复 UUID,使用
uuidgen生成新 UUID - 虚拟接口创建失败:检查 dummy 模块是否正确加载,使用
lsmod | grep dummy验证
4.9.7 SRE 经验总结
- 可预测接口名:现代 Linux 发行版默认使用可预测接口名(如
ens160),基于 PCI 设备路径 - 传统命名优势:在某些场景下,传统的
eth0命名更便于脚本编写和自动化管理 - 配置一致性:修改接口名时,必须确保所有相关配置文件保持一致
- 多种重命名方式:根据实际需求选择合适的重命名方法
- 虚拟接口应用:使用 dummy 模块可以创建纯虚拟的网络接口,适用于测试、负载均衡等场景
5. 总结
网络协议看似枯燥,实则是分布式系统的血管。作为 SRE,我们不需要成为网络专家,但必须掌握:
- 分层排查思维:是 DNS 问题?TCP 连接问题?还是应用层 HTTP 报错?
- 状态机理解:看到
CLOSE_WAIT知道找开发修 Bug,看到TIME_WAIT知道调内核参数。 - 工具熟练度:能够迅速用
ss看状态,用tcpdump抓现场。
只有这样,我们才能在故障发生时,从容不迫地定位根因,保障系统的稳定性。
文档信息
- 本文作者:soveran zhong
- 本文链接:https://blog.clockwingsoar.cn/2025/11/23/network-protocols-communication-sre/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)